
Heute werden wir uns mit dem AWS CDK beschäftigen, einem äußerst nützlichen Werkzeug zur Erstellung Ihrer Infrastruktur in der AWS-Cloud.
Mit CDK können Sie schnell Infrastruktur über Code erstellen und dabei Sprachen verwenden, die wir bereits in unserem täglichen Leben nutzen, wie TypeScript, Python, Java. Um die Komplexität der Verwaltung Ihrer Infrastruktur zu reduzieren und alles automatisiert zu gestalten, könnte CDK die ideale Option für Sie sein.
IaC
Bevor wir über CDK sprechen, ist es wichtig zu verstehen, was Infrastruktur als Code bedeutet.
Infrastruktur als Code (IaC) ist eine Möglichkeit, Infrastrukturressourcen mittels Code zu erstellen und zu verwalten, anstatt alles über eine Webseite oder durch Befehle in einem Terminal zu konfigurieren.
Nehmen wir an, Sie müssen einen Webserver in der Cloud erstellen. Anstatt zur AWS-Konsole zu gehen und eine Menge Buttons zu klicken, um Ihren Server manuell zu erstellen, können Sie Code schreiben, der alle Serverkonfigurationen detailliert, wie den Instanztyp, die Festplattengröße, wie viel Speicher dieser Server haben wird und Netzwerkeinstellungen.
Sie können dann diesen Code ausführen, um den Server automatisch auf AWS zu erstellen und zu konfigurieren. Dies ist nützlich, weil Sie den Prozess so oft wiederholen können, wie Sie möchten, ohne sich Sorgen machen zu müssen, eine wichtige Konfiguration zu vergessen. Zudem können Sie diese Ressourcen wie Code verwalten, in Ihrem Git-Repository speichern, den gesamten Änderungshistorie haben und natürlich Code-Überprüfungen an Ihrem Infrastruktur-Code vornehmen.
Infrastruktur durch Code mag kompliziert klingen, ist es aber nicht. Heutzutage konfiguriert niemand Anwendungen manuell, die Risiken, dies in realen Anwendungen zu tun, sind zu hoch. Deshalb sind Infrastruktur-als-Code-Tools (wie CDK) so wichtig. Und übrigens, viel lustiger als Buttons zu klicken, oder?!
CDK & Cloud Formation
Es gibt mehrere Infrastructure as Code Tools auf dem Markt. Hier, mehr im Kontext von AWS, sprechen wir über CDK und CloudFormation. Beide sind Werkzeuge, die Entwicklern helfen, Infrastrukturressourcen in der Cloud zu erstellen und zu verwalten. Das CDK wurde auf der Grundlage des CloudFormation-Add-Ons erstellt, und ich werde erklären, warum.
CloudFormation ist älter und verwendet JSON- oder YAML-Dateien, um die Infrastruktur zu beschreiben, die Sie erstellen möchten. Sie müssen wissen, wie man diese Dateien in der richtigen Syntax schreibt, und manchmal kann es ein bisschen unübersichtlich werden und die Dateien können ziemlich groß werden. Mit CloudFormation beschreiben Sie genau, wie Ihre Infrastruktur aussehen wird.
AWS CDK ist ein wenig anders, da es Ihnen erlaubt, Programmiersprachen wie TypeScript, Python, Java zu verwenden, um Ihre Infrastruktur zu beschreiben. Sie können komplexe und ausgeklügelte Infrastrukturen mit Klassen und Objekten erstellen, was den Infrastrukturcode für Entwickler vertrauter macht.
Außerdem können Sie mit CDK Code wiederverwenden und teilen, um Zeit zu sparen. Es ist möglich, Komponenten zu erstellen und diese in Ihrem Unternehmen zu teilen, indem beispielsweise Bibliotheken erstellt werden, die Standardkonfigurationen enthalten, die von mehreren Teams in Ihrem Unternehmen genutzt werden können. Und natürlich gibt es auch Open-Source-Komponenten, die von der Community erstellt wurden.
Und warum habe ich gesagt, dass CDK ein CloudFormation-Add-On ist? Weil beim Kompilieren dieses CDK-Codes eine CloudFormation-Datei generiert wird, die zur Erstellung unserer Infrastruktur verwendet wird.
Ist CDK also immer die beste Option? NEIN! Eine Sache, die Sie immer im Hinterkopf behalten müssen, ist, dass CDK eine meinungsstarke Lösung ist. Was meine ich damit? CDK ist ein Tool, das auf CloudFormation aufbaut, und deshalb gibt es in diesem Tool mehrere Standardverhalten, die im Allgemeinen den CDK-Code kleiner machen im Vergleich zu CloudFormation, und das bedeutet nicht, dass sich diese Verhalten nicht mit neuen Versionen ändern. CloudFormation kann sehr ausführlich und ein bisschen schwieriger zu handhaben sein, aber andererseits beschreiben Sie mit CloudFormation genau, wie Ihre Infrastruktur aussehen sollte.
Unter Beachtung dessen kann es sein, dass CDK für einige sensiblere Bereiche Ihrer Infrastruktur nicht die beste Option ist. OK? Ich hoffe, der Unterschied ist klar.
Anwendung
Bevor wir in den Code einsteigen, müssen Sie die CDK CLI installiert haben. Ich lasse den Link in der Beschreibung, wo Sie dem Schritt-für-Schritt folgen können.
Werfen wir einen kurzen Blick auf die Implementierung der Anwendung und beginnen dann gemeinsam mit dem Aufbau der Infrastruktur.
Unsere Anwendung ist einfach und hat zwei Endpunkte:
- Ein POST-Typ-Endpunkt zum Aufzeichnen von Transaktionen.
- Wo wir ein Payload mit E-Mail, Wert, Währung usw. übergeben.
- Ein GET-Endpunkt, um alle am Tag durchgeführten Transaktionen aufzulisten
- wo wir die aufgezeichneten Daten sowie das Datum der Transaktion und eine ID haben.
Die beiden Endpunkte werden über Lambdas zusammen mit API Gateway ausgeführt und die Daten in einer DynamoDB-Datenbank gespeichert.
Der Link zum Code auf Github befindet sich ebenfalls in der Beschreibung.
Ich werde nicht auf Details zur Implementierung der Anwendung eingehen, da dies nicht der Fokus dieses Videos ist. Es sind nur 2 Lambdas, eine speichert Daten in unserer DynamoDB-Datenbank und die andere ruft sie ab. Wenn Sie mehr über Lambdas und DynamoDB erfahren möchten, hinterlassen Sie einen Kommentar und ich werde weitere Videos dazu machen.
Abonnieren Sie auch den Kanal und hinterlassen Sie ein Like, um den Kanal zu unterstützen und damit ich mehr Videos machen kann.
Projekt und Abhängigkeiten
Wenn wir in der Dokumentation nachsehen, werden wir feststellen, dass es möglich ist, ein Projekt mit dem Befehl cdk init zu erstellen. Dieses Projekt wurde mit diesem Befehl erstellt und ich habe ein paar andere Abhängigkeiten hinzugefügt:
@aws-cdk/aws-lambda-nodejs
@types/aws-lambda
aws-sdk
- @aws-cdk/aws-lambda-nodejs und @types/aws-lambda
- um unsere Lambdas einfach mit NodeJS zu konfigurieren
- aws-sdk
- damit wir DynamoDB nutzen können
#!/usr/bin/env node
import 'source-map-support/register';
import * as cdk from 'aws-cdk-lib';
import { InitWithCDKTypescriptStack } from '../lib/init-with-cdk-typescript-stack';
const app = new cdk.App();
new InitWithCDKTypescriptStack(app, 'InitWithCdkTypescriptStack');
Stacks
Der Einstiegspunkt für einen CDK-Code zum Aufbau unserer Infrastruktur ist der bin Ordner.
In diesem Ordner haben wir eine Datei, die zusammen mit dem Projekt erstellt wird, und es ist diese Datei, die beginnt, unsere Infrastruktur zusammenzustellen.
Wir können sehen, dass die erste Zeile die Erstellung einer neuen CDK-Anwendung darstellt und dann erstellen wir einen neuen Stack und geben ihm eine ID.
In CDK ist ein “stack” im Grunde genommen eine Sammlung von Komponenten, die Sie erstellen können. Es ist eine Gruppe von Komponenten, die Sie stapeln und arrangieren können, wie es für Sie sinnvoll ist. Natürlich können Sie nur einen Stack haben, oder Sie können mehrere haben und sie nach Belieben organisieren.
Beispielsweise möchten Sie eine Webanwendung auf AWS erstellen. Sie können einen einzigen Stack erstellen, der Ihre EC2-Instanz zum Hosten der Anwendung, Sicherheitseinstellungen, einen S3-Bucket zum Speichern von Dateien und so weiter enthält.
Ein anderes Beispiel wäre die Aufteilung der Stacks in solche, die Daten hostende Dienste enthalten, und solche, die dies nicht tun. Also, s3 und DynamoDB in einem Stack, lambdas und API Gateway in einem anderen.
Um einen Stack zu erstellen, benötigen wir eine Klasse, die cdk.stack erweitert und in dieser Klasse können wir die Komponenten auflisten, die zu diesem Stack gehören sollen.
Es ist gut zu erwähnen, dass die Stacks und die Komponenten, die wir erstellen werden, sich im lib-Ordner befinden. Der bin-Ordner wird nur verwendet, um dem CDK zu signalisieren, wo die Infrastrukturdeklaration beginnt.
DynamoDB Stack
Lassen Sie uns zuerst unsere DynamoDB-Datenbank erstellen. Innerhalb einer neuen Datei erstellen wir eine TransactionsTable-Klasse und erweitern sie von Table.
import { AttributeType, Table } from "aws-cdk-lib/aws-dynamodb";
import { Construct } from "constructs";
export class TransactionsTable extends Table {
constructor(scope: Construct) {
super(scope, 'TRANSACTIONS_TABLE', {
partitionKey: { name: 'EMAIL', type: AttributeType.STRING },
sortKey: { name: 'CREATEDAT', type: AttributeType.STRING },
});
}
}
Die Klasse hat einen Konstruktor, der einen Parameter namens scope vom Typ Construct erhält. Dieser Parameter repräsentiert den Bereich, in dem die Tabelle erstellt wird. In unserem Fall ist dieser Bereich unser Haupt-Stack, InitWithCDKTypescriptStack.
Im Konstruktor der Table-Klasse müssen wir einige wichtige Informationen einfügen. Erstens geben wir der Tabelle einen Namen, der 'TRANSACTIONS_TABLE' lautet.
Ein schneller Tipp dazu: Wenn wir in unserem Code die Datenbank aufrufen und die Tabelle verwenden möchten, die wir erstellen, ist es nicht möglich, die Tabelle nur mit diesem Namen aufzurufen. Ressourcennamen in AWS müssen eindeutig sein, daher wird die Tabelle mit dem Namen erstellt, den wir angegeben haben, und AWS wird zur Unterscheidung eine Kennung anhängen, um sie eindeutig zu machen. Um diese Tabelle verwenden zu können, sehen wir im Anwendungscode, dass wir den tatsächlichen Namen der Tabelle über eine Umgebungsvariable erhalten. Dann verwenden wir einfach diese Variable als TableName.
Zurück zum Infrastrukturcode, geben wir als nächstes den partitionKey und sortKey für die Tabelle an. Der partitionKey kann verwendet werden, um jedes Element in der Tabelle eindeutig zu identifizieren. Das ist nicht unser Fall, da unser Partition Key das Feld 'EMAIL' ist und natürlich können wir mehr als eine Transaktion mit derselben E-Mail haben.
Wir verwenden das Feld 'CREATEDAT' als Sortierschlüssel. Der sortKey ist immer das Datum und die Uhrzeit, zu der diese Transaktion erstellt wurde, und wir werden ihn in unserer GET-API verwenden, um die Transaktionen nur auf die von heute zu filtern.
Der Trick hier ist, dass die Kombination dieser beiden Schlüssel diese Transaktion wirklich einzigartig macht. Diese Kombination wird Compositeschlüssel genannt.
import { NodejsFunction } from "aws-cdk-lib/aws-lambda-nodejs";
import { Construct } from "constructs";
import { Runtime } from "aws-cdk-lib/aws-lambda";
import { Table } from "aws-cdk-lib/aws-dynamodb";
interface PostNewTransactionLambdaParams {
transactionsTable: Table
}
export class PostNewTransactionLambda extends NodejsFunction {
constructor(scope: Construct, params: PostNewTransactionLambdaParams) {
super(scope, 'NewTransactionLambda', {
runtime: Runtime.NODEJS_18_X,
memorySize: 256,
bundling: {
minify: true,
sourceMap: true,
},
entry: "application/src/lambda/newTransactionLambda.ts",
handler: "handler",
environment: {
TRANSACTIONS_TABLE: params.transactionsTable.tableName
}
});
params.transactionsTable.grantReadWriteData(this);
}
}
Lambdas
Kommen wir zu unserem Lambdas-Code. Nun erstellen wir unsere 2 Lambdas. Fangen wir mit unserem POST-Lambda an. Auch hier werden wir eine Klasse erstellen und diesmal werden wir sie von NodeJSFunction erweitern.
import { Table } from "aws-cdk-lib/aws-dynamodb";
import { Runtime } from "aws-cdk-lib/aws-lambda";
import { NodejsFunction } from "aws-cdk-lib/aws-lambda-nodejs";
import { Construct } from "constructs";
interface TodayTransactionsLambdaParams {
transactionsTable: Table
}
export class GetTodayTransactionsLambda extends NodejsFunction {
constructor(scope: Construct, params: TodayTransactionsLambdaParams) {
super(scope, 'TodayTransactionsLambda', {
runtime: Runtime.NODEJS_18_X,
memorySize: 256,
bundling: {
minify: true,
sourceMap: true,
},
entry: "application/src/lambda/todayTransactionsLambda.ts",
handler: "handler",
environment: {
TRANSACTIONS_TABLE: params.transactionsTable.tableName
}
});
params.transactionsTable.grantReadData(this);
}
}
Im Konstruktor erhalten wir erneut den scope und einen neuen Parameter, params, der vom Typ PostNewTransactionLambdaParams ist. Lassen Sie uns dieses Interface oben definieren und diese params verwenden, um eine Referenz auf die Tabelle zu erhalten, die wir erstellt haben und die wir gleich unten verwenden werden.
Nun einige Einstellungen für unsere Lambda:
- NodeJS-Version: In diesem Fall verwenden wir die neueste LTS, die 18 ist.
- Menge des Speichers, den diese Lambda zuweisen wird: 256 MB.
- Bundling Einstellungen, um unseren Code zu komprimieren und unnötige Teile aus dem endgültigen Paket zu entfernen.
- Nun weisen wir darauf hin, welche Lambda zu dieser Konfiguration gehört. Also geben wir dort den Dateipfad an und im
handlerden Namen der Eingabefunktion in dieser Datei, die in unserem Fall auchhandlergenannt wird. - Denken Sie daran, ich sagte, um auf die Datenbank zuzugreifen, müssen wir den Tabellennamen über eine Umgebungsvariable erhalten? Dafür müssen wir definieren, welche Umgebungsvariablen diese Lambda haben wird. Also erstellen wir unsere Tabellennamen-Umgebungsvariable und verwenden die Referenz, die wir zu unserer Tabelle haben, um den tatsächlichen Namen dieser Tabelle in AWS zu erhalten.
- Als nächstes werden wir diese Tabellenreferenz auch verwenden, um unserer Lambda Schreib- und Leseberechtigungen zu erteilen.
Und unsere Einrichtung ist bereit. Unsere GET Lambda ist jetzt genau gleich, wir ändern nur den Lambda-Pfad und das Parameter-Interface. Auch in einem realen Projekt könnten Sie eine Basisklasse erstellen, die all diese Standardeinstellungen für alle Ihre Lambdas enthält.
API Gateway
Lass uns mit der Erstellung unserer finalen Komponente, dem API Gateway, fortfahren.
Anstatt eine Klasse mit einer spezifischen Komponente zu erweitern, wie wir es mit der Tabelle und den Lambda-Funktionen getan haben, werden wir hier eine allgemeinere Komponente verwenden, die als Construct bekannt ist. Es ist wichtig zu beachten, dass alle anderen Komponenten, die wir verwendet haben, im Grunde genommen auch Constructs sind, im Hintergrund.
import { NodejsFunction } from "aws-cdk-lib/aws-lambda-nodejs";
import * as apiGateway from "aws-cdk-lib/aws-apigateway";
import { Construct } from "constructs";
interface TransactionsGatewayParams {
postNewTransactionsLambda: NodejsFunction,
getTodayTransactionsLambda: NodejsFunction,
}
export class TransactionsGateway extends Construct {
constructor(scope: Construct, params: TransactionsGatewayParams) {
super(scope, 'TransactionsGateway');
const api = new apiGateway.RestApi(this, "TransactionsApi", {
restApiName: "New Transactions API",
description: "Backend Horizon - New Transactions API",
});
api.root.addMethod("POST", new apiGateway.LambdaIntegration(params.postNewTransactionsLambda, {
requestTemplates: { "application/json": '{ "statusCode": "200" }' },
}));
api.root.addMethod("GET", new apiGateway.LambdaIntegration(params.getTodayTransactionsLambda, {
requestTemplates: { "application/json": '{ "statusCode": "200" }' },
}));
}
}
Wir werden einen Konstruktor definieren, der die Parameter scope und params übernimmt, welche Referenzen zu unseren beiden Lambda-Funktionen enthalten.
Der nächste Schritt beinhaltet die Erstellung einer neuen Rest-API. Diese neu erstellte API wird mit mehreren Parametern konfiguriert:
- Wir werden unsere eigene Klasse
TransactionsGatewayals ersten Parameter übergeben. - Als nächstes weisen wir dieser API eine ID zu, die wir
TransactionsApinennen. - Außerdem setzen wir einen Namen und eine Beschreibung für diese API.
Der nächste Schritt besteht darin, unsere Lambdas mit dieser Rest-API zu verbinden. Wir werden eine POST-Methode an der Wurzel unserer API hinzufügen. Die Integration zwischen unserer Lambda-Funktion postNewTransactionsLambda und dieser API wird durch eine LambdaIntegration durchgeführt. Zusätzlich spezifizieren wir das Antwortformat, das diese API zurückgeben wird. Unter den verschiedenen in der Dokumentation verfügbaren Optionen wählen wir das application/json-Modell zusammen mit dem Statuscode (statusCode), was eine gängige Praxis ist.
Danach wiederholen wir diesen Prozess für die Lambda-Funktion getTodayTransactionsLambda, diesmal aber als GET-Methode.
import * as cdk from 'aws-cdk-lib';
import { Construct } from 'constructs';
import { TransactionsTable } from './dynamodb/transactions-table';
import { TransactionsGateway } from './gateway/transactions-gateway';
import { GetTodayTransactionsLambda } from './lambdas/get-today-transactions-lambda';
import { PostNewTransactionLambda } from './lambdas/post-new-transaction-lambda';
export class InitWithCDKTypescriptStack extends cdk.Stack {
constructor(scope: Construct, id: string, props?: cdk.StackProps) {
super(scope, id, props);
const transactionsTable = new TransactionsTable(this);
const postNewTransactionsLambda = new PostNewTransactionLambda(this, { transactionsTable });
const getTodayTransactionsLambda = new GetTodayTransactionsLambda(this, { transactionsTable });
new TransactionsGateway(this, { postNewTransactionsLambda: postNewTransactionsLambda, getTodayTransactionsLambda });
}
}
Main Stack
Jetzt, da alle unsere Komponenten erstellt sind, ist es Zeit, sie zu verbinden. Es wird ziemlich einfach sein.
Firstly, we take the TransactionsTable Komponente, welche wir zuvor entwickelt haben. Beim Erstellen dieser Komponente übergeben wir unseren Stack als Argument für den scope Parameter.
Als nächstes instanziieren und integrieren wir unsere zwei Lambdas. Beide benötigen den Stack und das neu erstellte transactionsTable als Parameter.
Unser letzter Schritt in dieser Phase beinhaltet das Einrichten unseres Gateways. Hier übergeben wir den aktuellen Stack und die zuvor eingerichteten Lambdas als Argumente.
Damit ist die primäre Stack-Konstruktion abgeschlossen. Der nächste Schritt besteht darin, diesen Stack und die Anwendung auf AWS bereitzustellen.
Bereitstellung
Bevor wir unsere Anwendung bereitstellen, müssen wir den „Bootstrapping“-Prozess initiieren. Dies ist ein einmaliger Voraussetzungsschritt.
- Beginnen Sie mit der Ausführung des Befehls
npm run cdk bootstrap. - Nach erfolgreichem Abschluss fahren Sie mit der Bereitstellung fort, indem Sie
npm run cdk deployverwenden. Ein Überblick der ausstehenden Änderungen wird angezeigt. Bitte bestätigen Sie diese Änderungen.
Sobald die Bereitstellung abgeschlossen ist, zeigt das Terminal die Basis-URL für Ihre APIs an, sodass Sie sie testen können.

Testen
Da unsere Anwendung nun bereitgestellt ist, ist es Zeit zum Testen.
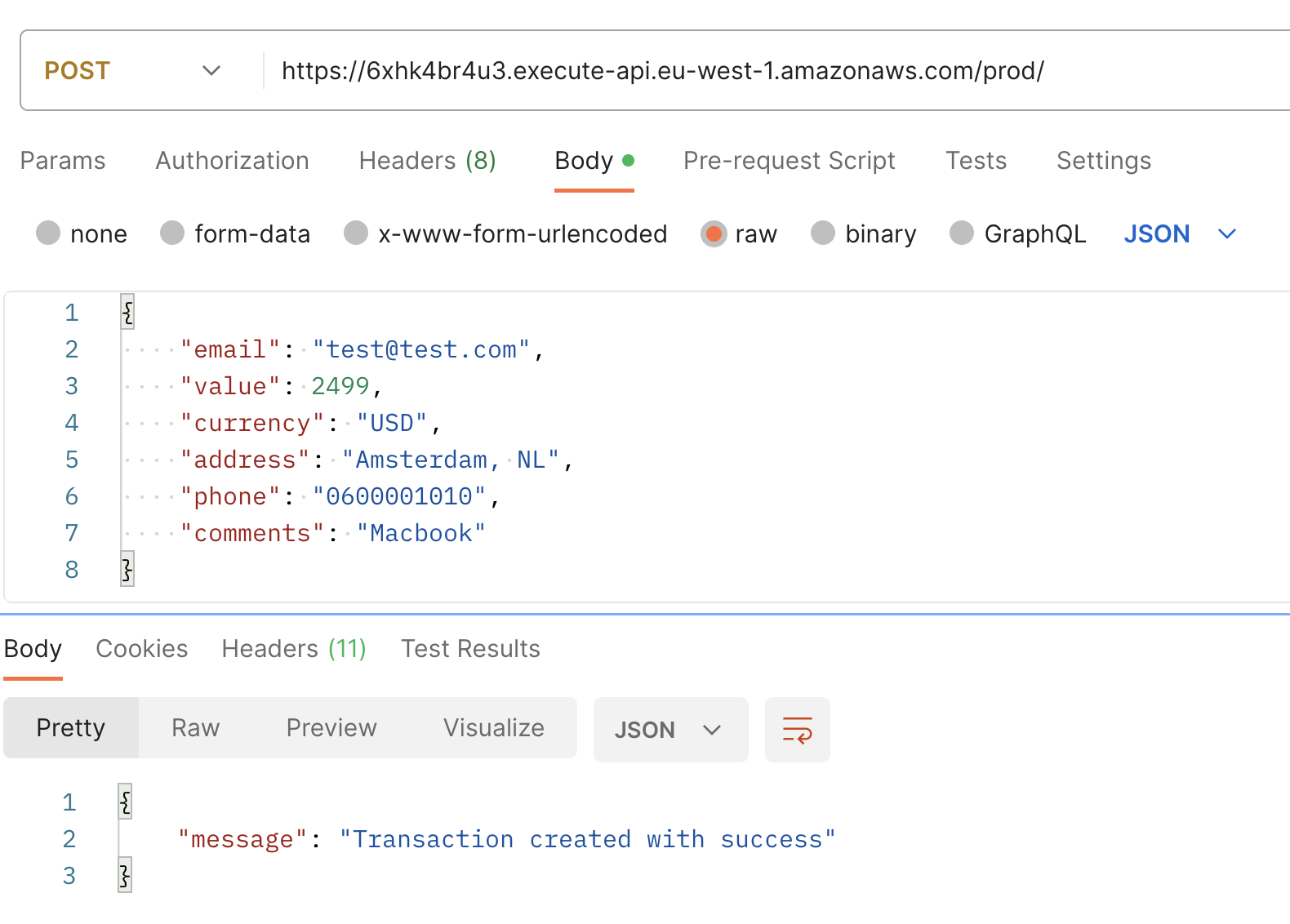
Verwenden Sie die in Ihrer Konsole angezeigte Basis-URL, um eine POST-Anfrage mit der folgenden Beispiel-Nutzlast zu stellen. Als Antwort sollten Sie eine Nachricht erhalten, die besagt: “Transaction created with success.”
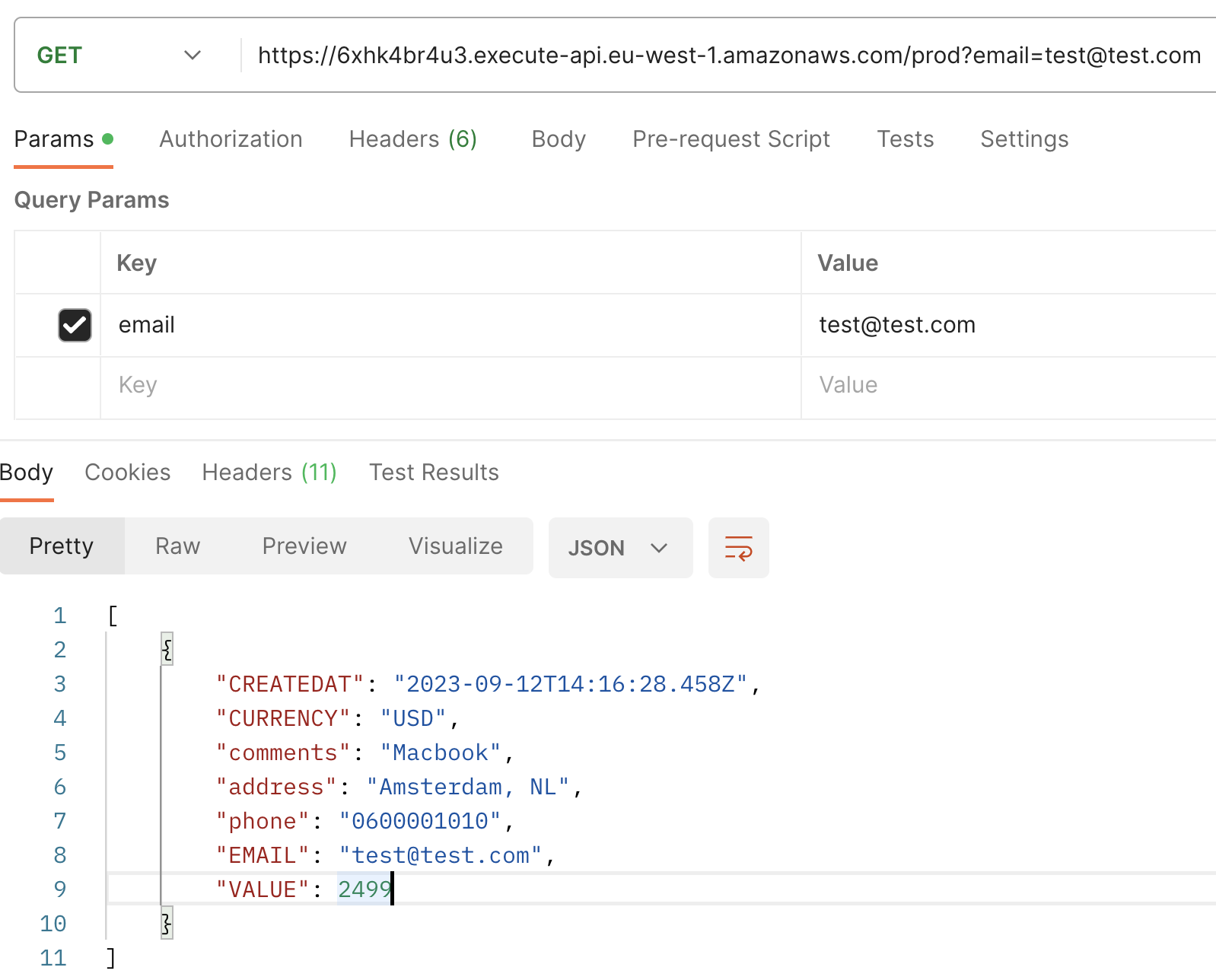
Wenn Sie dann eine GET-Anfrage mit der E-Mail als Abfrageparameter ausführen, werden Sie die kürzlich erstellte Transaktion sehen, die jetzt mit einem zusätzlichen Feld erweitert wurde: CREATEDAT.
Und wir sind endlich fertig. 🎉🎉🎉
Sie können das gesamte Projekt auf GitHub finden.
Fragen oder Vorschläge, bitte hinterlassen Sie einen Kommentar, wir sind alle hier, um gemeinsam zu lernen. 🤠
Danke fürs Lesen!


