
Hoy vamos a aprender sobre el AWS CDK, que es una herramienta súper útil para crear tu infraestructura en la nube de AWS.
Con CDK, puedes crear rápidamente infraestructura mediante código y utilizando lenguajes que ya usamos en nuestra vida diaria, como TypeScript, Python, Java. Así que, para reducir la complejidad de gestionar tu infraestructura y todo de manera automatizada, CDK puede ser la opción ideal para ti.
IaC
Antes de hablar sobre CDK es importante entender qué es la infraestructura como código.
La infraestructura como código (IaC) es una forma de crear y gestionar recursos de infraestructura utilizando código en lugar de configurar todo a través de una página web o mediante comandos en una terminal.
Digamos que necesitas crear un servidor web en la nube. En lugar de ir a la consola de AWS y hacer clic en varios botones para crear manualmente tu servidor, puedes escribir código que detalle todas las configuraciones del servidor, como el tipo de instancia, tamaño del disco, cuánta memoria tendrá este servidor y configuraciones de red.
Luego puedes ejecutar este código para crear y configurar automáticamente el servidor en AWS. Esto es útil porque puedes repetir el proceso tantas veces como quieras, sin preocuparte por olvidar una configuración importante, y también puedes gestionar estos recursos como si fueran código, guardarlos en tu repositorio git, tener todo el historial de cambios y, por supuesto, hacer revisiones de código en tu infraestructura de código.
La infraestructura como código puede sonar complicada, pero no lo es. Hoy en día, nadie configura aplicaciones manualmente, los riesgos de hacer esto en aplicaciones reales son demasiado altos. Por eso, las herramientas de infraestructura como código (como CDK) son tan importantes. ¡Y por cierto, mucho más divertido que hacer clic en botones, ¿verdad?!
CDK y CloudFormation
Hay varias herramientas de infraestructura como código en el mercado. Aquí, más en el contexto de AWS, hablemos de CDK y CloudFormation. Ambas son herramientas que ayudan a los desarrolladores a construir y gestionar recursos de infraestructura en la nube. El CDK se creó sobre el complemento de CloudFormation, y explicaré por qué.
CloudFormation es más antiguo y utiliza archivos JSON o YAML para describir la infraestructura que deseas construir. Necesitas saber cómo escribir estos archivos en la sintaxis correcta, y a veces puede ser un poco complicado y los archivos pueden llegar a ser bastante grandes. Con CloudFormation, describes precisamente cómo se verá tu infraestructura.
AWS CDK es un poco diferente ya que te permite usar lenguajes de programación como TypeScript, Python, Java para describir tu infraestructura. Puedes crear infraestructuras complejas y sofisticadas usando clases y objetos, lo que hace que el código de infraestructura sea más familiar para los desarrolladores.
Además, con CDK, puedes reutilizar y compartir código para ahorrar tiempo. Es posible crear componentes y compartirlos en tu empresa, creando bibliotecas, por ejemplo, que tengan configuraciones estándar que puedan ser utilizadas por varios equipos en tu empresa. Y por supuesto, hay componentes de código abierto hechos por la comunidad.
¿Y por qué dije que CDK es un complemento de CloudFormation? Porque cuando compilamos este código CDK, lo que se generará es un archivo CloudFormation, que se utilizará para crear nuestra infraestructura.
Entonces, ¿es CDK la mejor opción siempre? ¡NO! Una cosa que siempre debes tener en cuenta es que el CDK es una solución con opiniones. ¿Qué quiero decir con eso? El CDK es una herramienta construida sobre CloudFormation y, por eso, hay varios comportamientos por defecto en esta herramienta, lo que generalmente hace que el código CDK sea más pequeño en comparación con CloudFormation, y eso no significa que estos comportamientos no cambien con nuevas versiones. CloudFormation puede ser muy detallado y un poco más complicado de trabajar, pero por otro lado, con CloudFormation describes precisamente cómo debe ser tu infraestructura.
Entonces, teniendo eso en cuenta, puede ser que para algunas áreas más sensibles de tu infraestructura, CDK no sea la mejor opción. ¿De acuerdo? Espero que la diferencia esté clara.
Aplicación
Antes de entrar en el código, necesitas tener instalado el CDK CLI. Dejaré el enlace en la descripción, donde puedes seguir el paso a paso.
Echemos un vistazo rápido a la implementación de la aplicación y luego comencemos a construir la infraestructura juntos.
Nuestra aplicación es simple y tiene dos endpoints:
- Un endpoint de tipo POST para registrar transacciones.
- Donde pasamos un payload con email, value, currency, etc.
- Un endpoint GET para listar todas las transacciones realizadas en el día
- donde tendremos los datos que registramos, más la fecha en la que se realizó la transacción y un ID
Los dos endpoints se ejecutarán a través de lambdas junto con API Gateway y los datos se guardarán en una base de datos DynamoDB.
El enlace al código en Github también está en la descripción.
No entraré en detalles sobre la implementación de la aplicación, porque no es el enfoque de este video. Son solo 2 lambdas, una guardando datos en nuestra base de datos DynamoDB y la otra recuperándolos. Si quieres saber más sobre Lambdas y DynamoDB, deja un comentario y haré otros videos sobre ello.
Y también suscríbete al canal y deja un like para ayudar a que el canal crezca y pueda hacer más videos.
Proyecto y dependencias
Si miramos en la documentación veremos que es posible crear un proyecto usando el comando cdk init. Este proyecto fue creado usando este comando y agregué algunas otras dependencias:
@aws-cdk/aws-lambda-nodejs
@types/aws-lambda
aws-sdk
- @aws-cdk/aws-lambda-nodejs y @types/aws-lambda
- [Traducción de ’to easily configure our lambdas with’] NodeJS
- aws-sdk
- [Traducción de ‘for us to use’] DynamoDB
Stacks
El punto de entrada para un código CDK para comenzar a construir nuestra infraestructura es la carpeta bin.
Dentro de esa carpeta, tendremos un archivo que se creará junto con el proyecto, y es este archivo el que comenzará a ensamblar nuestra infraestructura.
#!/usr/bin/env node
import 'source-map-support/register';
import * as cdk from 'aws-cdk-lib';
import { InitWithCDKTypescriptStack } from '../lib/init-with-cdk-typescript-stack';
const app = new cdk.App();
new InitWithCDKTypescriptStack(app, 'InitWithCdkTypescriptStack');
Podemos ver que la primera línea es la creación de una nueva aplicación CDK y luego creamos un nuevo stack y le damos un id.
En CDK, un “stack” es básicamente una colección de componentes que puedes crear. Es un conjunto de componentes que puedes apilar y arreglar de una manera que tenga sentido para ti. Por supuesto, puedes tener solo un stack, o puedes tener varios y organizarlos como prefieras.
Por ejemplo, supongamos que deseas construir una aplicación web en AWS. Puedes crear un único stack que tendrá tu instancia EC2 para alojar la aplicación, configuraciones de seguridad, un bucket S3 para almacenar archivos, y así sucesivamente.
Otro ejemplo sería dividir en stacks que contengan servicios que alojan datos y otros que no. Entonces, s3 y DynamoDB en un stack, lambdas y API Gateway en otro.
Para crear un stack, necesitamos una clase que extienda cdk.stack y dentro de esa clase podemos comenzar a listar los componentes que pertenecerán a ese stack.
Es bueno mencionar que los stacks y los componentes que vamos a crear están en la carpeta lib. La carpeta bin solo se usa para señalar al CDK dónde comienza la declaración de la infraestructura.
DynamoDB Stack
Primero, creemos nuestra base de datos DynamoDB. Dentro de un nuevo archivo, creemos una clase TransactionsTable y extiéndela de Table.
import { AttributeType, Table } from "aws-cdk-lib/aws-dynamodb";
import { Construct } from "constructs";
export class TransactionsTable extends Table {
constructor(scope: Construct) {
super(scope, 'TRANSACTIONS_TABLE', {
partitionKey: { name: 'EMAIL', type: AttributeType.STRING },
sortKey: { name: 'CREATEDAT', type: AttributeType.STRING },
});
}
}
La clase tiene un constructor que recibe un parámetro llamado scope, de tipo Construct. Este parámetro representa el ámbito en el cual se está creando la tabla. En nuestro caso, este ámbito será nuestra pila principal, InitWithCDKTypescriptStack.
Dentro del constructor de la clase Table, necesitamos insertar información importante. Primero, le damos a la tabla un nombre, que es 'TRANSACTIONS_TABLE'.
Un consejo rápido sobre esto: cuando llamamos a la base de datos en nuestro código y queremos usar la tabla que estamos creando, no es posible llamar a la tabla usando solo este nombre. Los nombres de recursos en AWS deben ser únicos, por lo que la tabla se creará con el nombre que le dimos y AWS agregará un identificador para hacerlo único. Para poder usar esta tabla, en el código de la aplicación podemos ver que obtenemos el nombre real de la tabla a través de una variable de entorno. Luego, simplemente usamos esta variable como TableName.
Volviendo al código de infraestructura, luego especificamos el partitionKey y el sortKey para la tabla. El partitionKey se puede usar para identificar de manera única cada elemento en la tabla. Este no es nuestro caso, ya que nuestra clave de partición es el campo 'EMAIL' y, por supuesto, podemos tener más de una transacción con el mismo correo electrónico.
Estamos usando el campo 'CREATEDAT' como la clave de ordenación. El sortKey es siempre la fecha y hora en que se creó esta transacción y lo vamos a usar en nuestra API GET para filtrar las transacciones únicamente a las realizadas hoy.
El truco aquí es que la combinación de estas dos claves es lo que realmente hace que esta transacción sea única. Esta combinación se llama Clave Compuesta.
Lambdas
Pasando a nuestro código de lambdas. Ahora vamos a crear nuestras 2 lambdas. Empecemos con nuestra lambda POST. Aquí nuevamente vamos a crear una clase y esta vez la vamos a extender de NodeJSFunction.
import { NodejsFunction } from "aws-cdk-lib/aws-lambda-nodejs";
import { Construct } from "constructs";
import { Runtime } from "aws-cdk-lib/aws-lambda";
import { Table } from "aws-cdk-lib/aws-dynamodb";
interface PostNewTransactionLambdaParams {
transactionsTable: Table
}
export class PostNewTransactionLambda extends NodejsFunction {
constructor(scope: Construct, params: PostNewTransactionLambdaParams) {
super(scope, 'NewTransactionLambda', {
runtime: Runtime.NODEJS_18_X,
memorySize: 256,
bundling: {
minify: true,
sourceMap: true,
},
entry: "application/src/lambda/newTransactionLambda.ts",
handler: "handler",
environment: {
TRANSACTIONS_TABLE: params.transactionsTable.tableName
}
});
params.transactionsTable.grantReadWriteData(this);
}
}
En el constructor, nuevamente recibiremos el scope y un nuevo parámetro, params, que es del tipo PostNewTransactionLambdaParams. Vamos a definir esta interfaz arriba y usar estos params para recibir una referencia a la tabla que creamos, la cual usaremos justo a continuación.
Ahora algunos ajustes para nuestra lambda:
- Versión de NodeJS: en este caso, usaremos la última LTS, que es la 18.
- Cantidad de memoria que esta lambda asignará: 256 MB.
- Configuraciones de empaquetado para comprimir nuestro código y sacar del paquete final lo que no sea necesario.
- Ahora, señalemos cuál lambda pertenece a esta configuración. Entonces, pasamos la ruta del archivo allí y, en
handler, el nombre de la función de entrada en ese archivo, que en nuestro caso también se llamahandler. - Recuerda que dije que, para acceder a la base de datos, necesitamos obtener el nombre de la tabla a través de una variable de entorno? Para esto, necesitamos definir qué variables de entorno tendrá esta lambda. Así que vamos a crear nuestra variable de entorno para el nombre de la tabla y usaremos la referencia que tenemos a nuestra tabla para obtener el nombre real de esa tabla en AWS.
- A continuación, también vamos a usar esa referencia de tabla para otorgar permisos de escritura y lectura a nuestra lambda.
Y nuestra configuración está lista. Ahora nuestra lambda GET es exactamente la misma, solo vamos a cambiar la ruta de la lambda y la interfaz de parámetros. Incluso en un proyecto real, podrías estar creando una clase base que tenga todas estas configuraciones predeterminadas para todas tus lambdas.
import { Table } from "aws-cdk-lib/aws-dynamodb";
import { Runtime } from "aws-cdk-lib/aws-lambda";
import { NodejsFunction } from "aws-cdk-lib/aws-lambda-nodejs";
import { Construct } from "constructs";
interface TodayTransactionsLambdaParams {
transactionsTable: Table
}
export class GetTodayTransactionsLambda extends NodejsFunction {
constructor(scope: Construct, params: TodayTransactionsLambdaParams) {
super(scope, 'TodayTransactionsLambda', {
runtime: Runtime.NODEJS_18_X,
memorySize: 256,
bundling: {
minify: true,
sourceMap: true,
},
entry: "application/src/lambda/todayTransactionsLambda.ts",
handler: "handler",
environment: {
TRANSACTIONS_TABLE: params.transactionsTable.tableName
}
});
params.transactionsTable.grantReadData(this);
}
}
API Gateway
Procedamos con la creación de nuestro componente final, el API Gateway.
En lugar de extender una clase con un componente específico, como hicimos con la tabla y las funciones lambda, utilizaremos un componente más genérico aquí, conocido como Construct. Es crucial notar que todos los otros componentes que hemos utilizado son también esencialmente Constructs, detrás de escena.
import { NodejsFunction } from "aws-cdk-lib/aws-lambda-nodejs";
import * as apiGateway from "aws-cdk-lib/aws-apigateway";
import { Construct } from "constructs";
interface TransactionsGatewayParams {
postNewTransactionsLambda: NodejsFunction,
getTodayTransactionsLambda: NodejsFunction,
}
export class TransactionsGateway extends Construct {
constructor(scope: Construct, params: TransactionsGatewayParams) {
super(scope, 'TransactionsGateway');
const api = new apiGateway.RestApi(this, "TransactionsApi", {
restApiName: "New Transactions API",
description: "Backend Horizon - New Transactions API",
});
api.root.addMethod("POST", new apiGateway.LambdaIntegration(params.postNewTransactionsLambda, {
requestTemplates: { "application/json": '{ "statusCode": "200" }' },
}));
api.root.addMethod("GET", new apiGateway.LambdaIntegration(params.getTodayTransactionsLambda, {
requestTemplates: { "application/json": '{ "statusCode": "200" }' },
}));
}
}
Definiremos un constructor que tomará los parámetros scope y params, los cuales contendrán referencias a nuestras dos funciones lambda.
El siguiente paso implica crear una nueva Rest API. Esta API recién creada será configurada con varios parámetros:
- Pasaremos nuestra propia clase
TransactionsGatewaycomo el primer parámetro. - Luego, asignaremos un ID a esta API, que llamaremos
TransactionsApi. - Además, estableceremos un nombre y una descripción para esta API.
El siguiente paso es conectar nuestras lambdas a esta Rest API. Añadiremos un método POST en la raíz de nuestra API. La integración entre nuestra función lambda postNewTransactionsLambda y esta API se llevará a cabo a través de un LambdaIntegration. Adicionalmente, especificaremos el formato de respuesta que devolverá esta API. Entre las diversas opciones disponibles en la documentación, elegiremos usar el modelo application/json, junto con el código de estado (statusCode), lo cual es una práctica común.
Después, repetiremos este proceso para la función lambda getTodayTransactionsLambda, pero esta vez, configurándola como un método GET.
Main Stack
Ahora que todos nuestros componentes están creados, es hora de conectarlos. Será bastante sencillo.
import * as cdk from 'aws-cdk-lib';
import { Construct } from 'constructs';
import { TransactionsTable } from './dynamodb/transactions-table';
import { TransactionsGateway } from './gateway/transactions-gateway';
import { GetTodayTransactionsLambda } from './lambdas/get-today-transactions-lambda';
import { PostNewTransactionLambda } from './lambdas/post-new-transaction-lambda';
export class InitWithCDKTypescriptStack extends cdk.Stack {
constructor(scope: Construct, id: string, props?: cdk.StackProps) {
super(scope, id, props);
const transactionsTable = new TransactionsTable(this);
const postNewTransactionsLambda = new PostNewTransactionLambda(this, { transactionsTable });
const getTodayTransactionsLambda = new GetTodayTransactionsLambda(this, { transactionsTable });
new TransactionsGateway(this, { postNewTransactionsLambda: postNewTransactionsLambda, getTodayTransactionsLambda });
}
}
Primero, tomamos el componente TransactionsTable, que desarrollamos anteriormente. Al crear este componente, pasaremos nuestro Stack como argumento para el parámetro scope.
A continuación, instaciaremos e integraremos nuestras dos lambdas. Ambas requerirán el Stack y el recién creado transactionsTable como parámetros.
Nuestro paso final en esta fase implica configurar nuestro Gateway. Aquí, proporcionaremos el stack actual y las lambdas que configuramos anteriormente como argumentos.
Con esto, finaliza la construcción principal de nuestro Stack. El siguiente paso es desplegar este stack y la aplicación en AWS.
Despliegue
Antes de desplegar nuestra aplicación, necesitamos iniciar el proceso de “bootstrapping”. Este es un paso previo único.
- Comienza ejecutando el comando
npm run cdk bootstrap. - Una vez completado con éxito, procede con el despliegue utilizando
npm run cdk deploy. Se mostrará una visión general de los cambios pendientes. Por favor, confirma estos cambios.
Una vez que el despliegue concluya, la terminal mostrará la URL base para tus APIs, lo que te permitirá probarlas.

Pruebas
Con nuestra aplicación ahora desplegada, es hora de realizar pruebas.
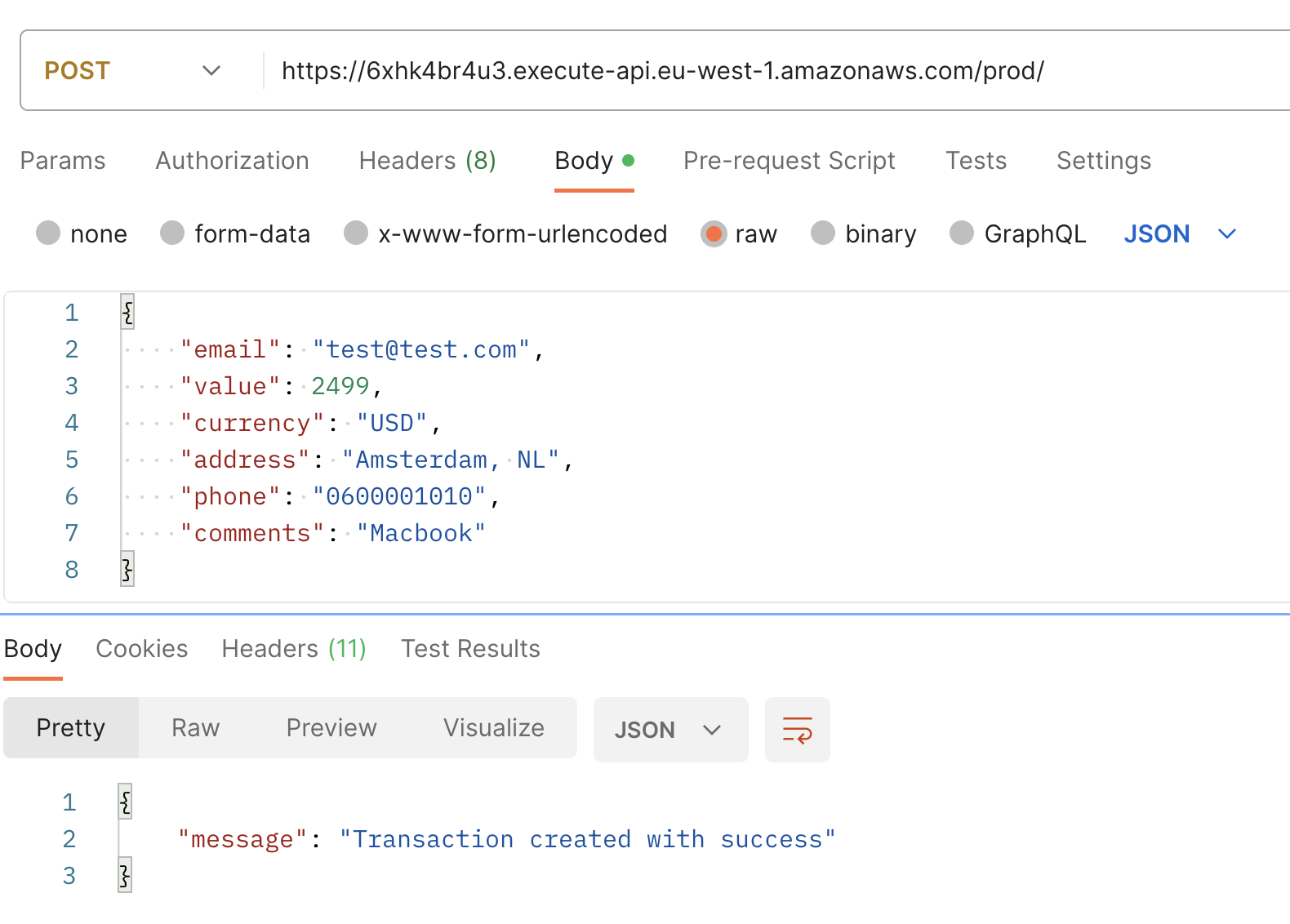
Utiliza la URL base mostrada en tu consola para hacer una POST request, usando el siguiente payload de ejemplo. En respuesta, deberías recibir un mensaje que indique “Transacción creada con éxito.”
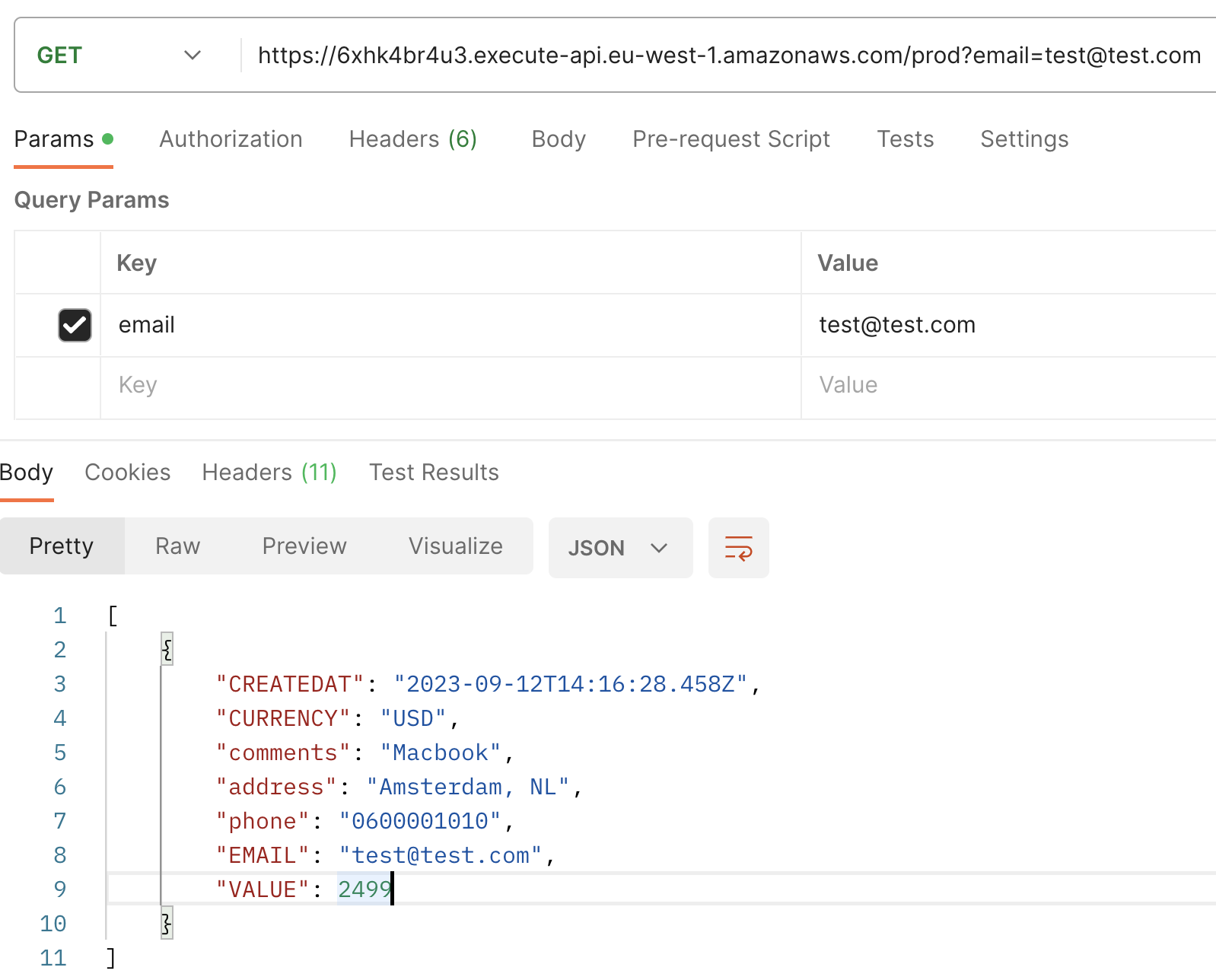
Luego, cuando ejecutes una GET request con el email como parámetro de consulta, observarás la transacción recién creada, ahora incrementada con un campo adicional: CREATEDAT.
Y finalmente hemos terminado. 🎉🎉🎉
Puedes encontrar el proyecto completo en GitHub.
Preguntas o sugerencias, por favor deja un comentario, todos estamos aquí para aprender juntos. 🤠
¡Gracias por leer!


