
Aujourd’hui, nous allons apprendre à propos de AWS CDK, qui est un outil très utile pour créer votre infrastructure dans le cloud AWS.
Avec CDK, vous pouvez rapidement créer une infrastructure via du code et en utilisant des langages que nous utilisons déjà dans notre vie quotidienne, tels que TypeScript, Python, Java. Ainsi, pour réduire la complexité de la gestion de votre infrastructure et tout de manière automatisée, CDK peut être l’option idéale pour vous.
IaC
Avant de parler de CDK, il est important de comprendre ce qu’est l’infrastructure en tant que code.
L’infrastructure en tant que code (IaC) est une manière de créer et gérer des ressources d’infrastructure en utilisant du code, au lieu de tout configurer via une page web ou par des commandes dans un terminal.
Disons que vous avez besoin de créer un serveur web dans le cloud. Au lieu d’aller sur la console AWS et de cliquer sur une multitude de boutons pour créer manuellement votre serveur, vous pouvez écrire du code qui détaille toutes les configurations du serveur, telles que le type d’instance, la taille du disque, la quantité de mémoire de ce serveur et les paramètres réseau.
Vous pouvez ensuite exécuter ce code pour créer et configurer automatiquement le serveur sur AWS. C’est utile car vous pouvez répéter le processus autant de fois que vous le souhaitez, sans vous soucier d’oublier une configuration importante; vous pouvez également gérer ces ressources comme s’il s’agissait de code, les sauvegarder dans votre dépôt git, avoir tout l’historique des modifications et bien sûr, faire des revues de code de votre code d’infrastructure.
L’infrastructure par code peut sembler compliquée, mais ce n’est pas le cas. De nos jours, personne ne configure d’applications manuellement, les risques de le faire dans des applications réelles sont trop élevés. C’est pourquoi les outils d’infrastructure en tant que code (comme CDK) sont si importants. Et en passant, c’est bien plus amusant que de cliquer sur des boutons, non ?!
CDK & Cloud Formation
Il existe plusieurs outils d’infrastructure en tant que code sur le marché. Ici, dans le contexte d’AWS, parlons de CDK et CloudFormation. Les deux sont des outils qui aident les développeurs à construire et gérer les ressources d’infrastructure dans le cloud. Le CDK a été créé sur l’add-on de CloudFormation, et je vais expliquer pourquoi.
CloudFormation est plus ancien et utilise des fichiers JSON ou YAML pour décrire l’infrastructure que vous souhaitez construire. Vous devez savoir comment écrire ces fichiers dans la syntaxe correcte, et parfois cela peut être un peu désordonné et les fichiers peuvent devenir assez volumineux. Avec CloudFormation, vous décrivez précisément à quoi ressemblera votre infrastructure.
AWS CDK est un peu différent car il vous permet d’utiliser des langages de programmation comme TypeScript, Python, Java pour décrire votre infrastructure. Vous pouvez créer une infrastructure complexe et sophistiquée en utilisant des classes et des objets, ce qui rend le code d’infrastructure plus familier aux développeurs.
Aussi, avec le CDK, vous pouvez réutiliser et partager du code pour gagner du temps. Il est possible de créer des composants et de les partager dans votre entreprise, en créant par exemple des bibliothèques qui ont des configurations standard pouvant être utilisées par plusieurs équipes dans votre entreprise. Et bien sûr, il existe des composants open source créés par la communauté.
Et pourquoi ai-je dit que CDK est un add-on de CloudFormation ? Parce que lorsque nous compilons ce code CDK, ce qui sera généré est un fichier CloudFormation, qui sera utilisé pour créer notre infrastructure.
Donc, est-ce que CDK est la meilleure option à chaque fois ? NON ! Une chose que vous devez toujours garder à l’esprit est que le CDK est une solution opinionnée. Qu’est-ce que je veux dire par là ? Le CDK est un outil construit sur CloudFormation, et à cause de cela, il y a plusieurs comportements par défaut dans cet outil, ce qui rend généralement le code CDK plus petit par rapport à CloudFormation, et cela ne signifie pas que ces comportements ne changent pas avec les nouvelles versions. CloudFormation peut être très verbeux et un peu plus difficile à utiliser, mais d’autre part, avec CloudFormation, vous décrivez précisément à quoi votre infrastructure doit ressembler.
Donc, avec cela à l’esprit, il se peut que pour certaines zones plus sensibles de votre infrastructure, CDK ne soit pas la meilleure option. D’accord ? J’espère que la différence est claire.
Application
Avant de plonger dans le code, vous devez avoir le CDK CLI installé. Je laisserai le lien dans la description, où vous pouvez suivre les étapes.
Jetons un coup d’œil rapide à l’implémentation de l’application puis commençons à construire l’infrastructure ensemble.
Notre application est simple et possède deux points de terminaison :
- Un point de terminaison de type POST pour enregistrer les transactions.
- Où nous passons une charge utile avec email, valeur, devise, etc.
- Un point de terminaison GET pour lister toutes les transactions effectuées dans la journée
- où nous aurons les données que nous avons enregistrées, ainsi que la date à laquelle la transaction a été effectuée et un ID
Les deux points de terminaison seront exécutés via des lambdas avec API Gateway et les données seront sauvegardées dans une base de données DynamoDB.
Le lien vers le code sur Github est également dans la description.
Je ne vais pas entrer dans les détails de l’implémentation de l’application, car ce n’est pas le focus de cette vidéo. Ce sont juste 2 lambdas, l’un sauvegardant les données dans notre base de données DynamoDB et l’autre les récupérant. Si vous voulez en savoir plus sur les Lambdas et DynamoDB, laissez un commentaire et je ferai d’autres vidéos à ce sujet.
Et abonnez-vous également à la chaîne et laissez un like pour aider la chaîne à grandir et afin que je puisse faire plus de vidéos.
Projet et dépendances
Si nous regardons dans la documentation, nous verrons qu’il est possible de créer un projet en utilisant la commande cdk init. Ce projet a été créé en utilisant cette commande et j’ai ajouté quelques autres dépendances :
@aws-cdk/aws-lambda-nodejs
@types/aws-lambda
aws-sdk
- @aws-cdk/aws-lambda-nodejs et @types/aws-lambda
- pour configurer facilement nos lambdas avec NodeJS
- aws-sdk
- pour que nous puissions utiliser DynamoDB
Stacks
Le point d’entrée pour un code CDK pour commencer à construire notre infrastructure est le dossier bin.
À l’intérieur de ce dossier, nous aurons un fichier qui sera créé avec le projet, et c’est ce fichier qui commencera à assembler notre infrastructure.
#!/usr/bin/env node
import 'source-map-support/register';
import * as cdk from 'aws-cdk-lib';
import { InitWithCDKTypescriptStack } from '../lib/init-with-cdk-typescript-stack';
const app = new cdk.App();
new InitWithCDKTypescriptStack(app, 'InitWithCdkTypescriptStack');
Nous pouvons voir que la première ligne est la création d’une nouvelle application CDK, puis nous créons une nouvelle stack et lui donnons un identifiant.
Dans CDK, une “stack” est essentiellement une collection de composants que vous pouvez créer. C’est un ensemble de composants que vous pouvez empiler et organiser d’une manière qui a du sens pour vous. Bien sûr, vous pouvez avoir juste une stack, ou vous pouvez en avoir plusieurs et les organiser comme vous le souhaitez.
Par exemple, disons que vous voulez construire une application web sur AWS. Vous pouvez créer une seule stack qui contiendra votre instance EC2 pour héberger l’application, les paramètres de sécurité, un bucket S3 pour stocker les fichiers, etc.
Ou un autre exemple serait de diviser les stacks en services qui hébergent des données et d’autres qui n’en hébergent pas. Ainsi, s3 et DynamoDB sur une stack, lambdas et API Gateway sur une autre.
Pour créer une stack, nous avons besoin d’une classe qui étend cdk.stack et à l’intérieur de cette classe, nous pouvons commencer à lister les composants qui appartiendront à cette stack.
Il est bon de mentionner que les stacks et les composants que nous allons créer se trouvent dans le dossier lib. Le dossier bin est uniquement utilisé pour indiquer au CDK où commence la déclaration de l’infrastructure.
DynamoDB Stack
Commençons par créer notre base de données DynamoDB. À l’intérieur d’un nouveau fichier, créons une classe TransactionsTable et étendons-la à partir de Table.
import { AttributeType, Table } from "aws-cdk-lib/aws-dynamodb";
import { Construct } from "constructs";
export class TransactionsTable extends Table {
constructor(scope: Construct) {
super(scope, 'TRANSACTIONS_TABLE', {
partitionKey: { name: 'EMAIL', type: AttributeType.STRING },
sortKey: { name: 'CREATEDAT', type: AttributeType.STRING },
});
}
}
La classe a un constructeur qui reçoit un paramètre appelé scope, de type Construct. Ce paramètre représente l’étendue dans laquelle la table est créée. Dans notre cas, cette étendue sera notre pile principale, InitWithCDKTypescriptStack.
À l’intérieur du constructeur de la classe Table, nous devons insérer quelques informations importantes. Tout d’abord, nous donnons un nom à la table, qui est 'TRANSACTIONS_TABLE'.
Un petit conseil à ce sujet : lorsque nous appelons la base de données dans notre code et que nous voulons utiliser la table que nous créons, il n’est pas possible d’appeler la table en utilisant uniquement ce nom. Les noms de ressources dans AWS doivent être uniques, donc la table sera créée avec le nom que nous avons donné et AWS ajoutera un identifiant pour la rendre unique. Afin de pouvoir utiliser cette table, dans le code de l’application, nous pouvons voir que nous obtenons le vrai nom de la table via une variable d’environnement. Ensuite, nous utilisons simplement cette variable comme TableName.
En revenant au code de l’infrastructure, nous spécifions ensuite le partitionKey et le sortKey pour la table. Le partitionKey peut être utilisé pour identifier de manière unique chaque élément de la table. Ce n’est pas notre cas, car notre clé de partition est le champ 'EMAIL' et, bien sûr, nous pouvons avoir plus d’une transaction avec le même email.
Nous utilisons le champ 'CREATEDAT' comme clé de tri. Le sortKey est toujours la date et l’heure à laquelle cette transaction a été créée et nous allons l’utiliser dans notre API GET pour filtrer les transactions uniquement à celles faites aujourd’hui.
L’astuce ici est que la combinaison de ces deux clés est ce qui rend vraiment cette transaction unique. Cette combinaison est appelée Composite Key.
Lambdas
Passons maintenant à notre code des lambdas. Créons maintenant nos 2 lambdas. Commençons par notre lambda POST. Ici encore, nous allons créer une classe et cette fois nous allons l’étendre à partir de NodeJSFunction.
import { NodejsFunction } from "aws-cdk-lib/aws-lambda-nodejs";
import { Construct } from "constructs";
import { Runtime } from "aws-cdk-lib/aws-lambda";
import { Table } from "aws-cdk-lib/aws-dynamodb";
interface PostNewTransactionLambdaParams {
transactionsTable: Table
}
export class PostNewTransactionLambda extends NodejsFunction {
constructor(scope: Construct, params: PostNewTransactionLambdaParams) {
super(scope, 'NewTransactionLambda', {
runtime: Runtime.NODEJS_18_X,
memorySize: 256,
bundling: {
minify: true,
sourceMap: true,
},
entry: "application/src/lambda/newTransactionLambda.ts",
handler: "handler",
environment: {
TRANSACTIONS_TABLE: params.transactionsTable.tableName
}
});
params.transactionsTable.grantReadWriteData(this);
}
}
Dans le constructeur, nous allons à nouveau recevoir le scope et un nouveau paramètre, params, qui est de type PostNewTransactionLambdaParams. Définissons cette interface ci-dessus et utilisons ce params pour recevoir une référence à la table que nous avons créée, que nous utiliserons juste en dessous.
Maintenant quelques réglages pour notre lambda :
- Version de NodeJS : dans ce cas, nous utiliserons la dernière LTS, qui est 18.
- Quantité de mémoire que cette lambda allouera : 256 MB.
- Paramètres de bundling pour compresser notre code et retirer du package final ce qui n’est pas nécessaire.
- Maintenant, indiquons à quelle lambda appartient cette configuration. Nous passons donc le chemin du fichier et, dans
handler, le nom de la fonction d’entrée dans ce fichier, qui, dans notre cas, s’appelle égalementhandler. - Rappelez-vous, j’ai dit que, pour accéder à la base de données, nous devons obtenir le nom de la table via une variable d’environnement ? Pour cela, nous devons définir quelles variables d’environnement cette lambda aura. Créons donc notre variable d’environnement pour le nom de la table et utilisons la référence que nous avons de notre table pour obtenir le nom réel de cette table dans AWS.
- Ensuite, nous allons également utiliser cette référence de table pour donner des permissions de lecture et d’écriture à notre lambda.
Et notre configuration est prête. Maintenant notre lambda GET est exactement la même, nous allons simplement changer le chemin de la lambda et l’interface des paramètres. Même dans un projet réel, vous pourriez créer une classe de base qui possède tous ces paramètres par défaut pour toutes vos lambdas.
import { Table } from "aws-cdk-lib/aws-dynamodb";
import { Runtime } from "aws-cdk-lib/aws-lambda";
import { NodejsFunction } from "aws-cdk-lib/aws-lambda-nodejs";
import { Construct } from "constructs";
interface TodayTransactionsLambdaParams {
transactionsTable: Table
}
export class GetTodayTransactionsLambda extends NodejsFunction {
constructor(scope: Construct, params: TodayTransactionsLambdaParams) {
super(scope, 'TodayTransactionsLambda', {
runtime: Runtime.NODEJS_18_X,
memorySize: 256,
bundling: {
minify: true,
sourceMap: true,
},
entry: "application/src/lambda/todayTransactionsLambda.ts",
handler: "handler",
environment: {
TRANSACTIONS_TABLE: params.transactionsTable.tableName
}
});
params.transactionsTable.grantReadData(this);
}
}
API Gateway
Proceedons avec la création de notre composant final, le API Gateway.
Au lieu d’étendre une classe avec un composant spécifique, comme nous l’avons fait avec la table et les fonctions lambda, nous utiliserons ici un composant plus générique, connu sous le nom de Construct. Il est crucial de noter que tous les autres composants que nous avons utilisés sont également essentiellement des Constructs, en coulisses.
import { NodejsFunction } from "aws-cdk-lib/aws-lambda-nodejs";
import * as apiGateway from "aws-cdk-lib/aws-apigateway";
import { Construct } from "constructs";
interface TransactionsGatewayParams {
postNewTransactionsLambda: NodejsFunction,
getTodayTransactionsLambda: NodejsFunction,
}
export class TransactionsGateway extends Construct {
constructor(scope: Construct, params: TransactionsGatewayParams) {
super(scope, 'TransactionsGateway');
const api = new apiGateway.RestApi(this, "TransactionsApi", {
restApiName: "New Transactions API",
description: "Backend Horizon - New Transactions API",
});
api.root.addMethod("POST", new apiGateway.LambdaIntegration(params.postNewTransactionsLambda, {
requestTemplates: { "application/json": '{ "statusCode": "200" }' },
}));
api.root.addMethod("GET", new apiGateway.LambdaIntegration(params.getTodayTransactionsLambda, {
requestTemplates: { "application/json": '{ "statusCode": "200" }' },
}));
}
}
Nous allons définir un constructeur qui prendra les paramètres scope et params, qui contiendront des références à nos deux fonctions lambda.
L’étape suivante consiste à créer une nouvelle API Rest. Cette API nouvellement créée sera configurée avec plusieurs paramètres :
- Nous passerons notre propre classe
TransactionsGatewayen tant que premier paramètre. - Ensuite, nous assignerons un ID à cette API, que nous appellerons
TransactionsApi. - De plus, nous définirons un nom et une description pour cette API.
L’étape suivante consiste à connecter nos lambdas à cette API Rest. Nous ajouterons une méthode POST à la racine de notre API. L’intégration entre notre fonction lambda postNewTransactionsLambda et cette API sera effectuée via une LambdaIntegration. De plus, nous spécifierons le format de réponse que cette API retournera. Parmi les différentes options disponibles dans la documentation, nous choisirons d’utiliser le modèle application/json, ainsi que le code de statut (statusCode), ce qui est une pratique courante.
Ensuite, nous répéterons ce processus pour la fonction lambda getTodayTransactionsLambda, mais cette fois-ci, en la configurant comme une méthode GET.
Pile Principale
Maintenant que tous nos composants sont créés, il est temps de les connecter. Ce sera assez simple.
import * as cdk from 'aws-cdk-lib';
import { Construct } from 'constructs';
import { TransactionsTable } from './dynamodb/transactions-table';
import { TransactionsGateway } from './gateway/transactions-gateway';
import { GetTodayTransactionsLambda } from './lambdas/get-today-transactions-lambda';
import { PostNewTransactionLambda } from './lambdas/post-new-transaction-lambda';
export class InitWithCDKTypescriptStack extends cdk.Stack {
constructor(scope: Construct, id: string, props?: cdk.StackProps) {
super(scope, id, props);
const transactionsTable = new TransactionsTable(this);
const postNewTransactionsLambda = new PostNewTransactionLambda(this, { transactionsTable });
const getTodayTransactionsLambda = new GetTodayTransactionsLambda(this, { transactionsTable });
new TransactionsGateway(this, { postNewTransactionsLambda: postNewTransactionsLambda, getTodayTransactionsLambda });
}
}
Tout d’abord, nous prenons le composant TransactionsTable que nous avons développé précédemment. Lors de la création de ce composant, nous passerons notre Stack en argument pour le paramètre scope.
Ensuite, nous allons instancier et intégrer nos deux lambdas. Les deux nécessiteront la Stack et le transactionsTable nouvellement créé comme paramètres.
Notre dernière étape dans cette phase consiste à configurer notre Gateway. Ici, nous fournirons la stack actuelle et les lambdas que nous avons précédemment configurés en tant qu’arguments.
Avec cela, la construction de notre Stack principale se termine. La prochaine étape consiste à déployer cette stack et l’application sur AWS.
Déploiement
Avant de déployer notre application, nous devons initier le processus de “bootstrapping”. Ceci est une étape préalable unique.
- Commencez par exécuter la commande
npm run cdk bootstrap. - Une fois cette étape terminée avec succès, procédez au déploiement en utilisant
npm run cdk deploy. Un aperçu des modifications en attente sera affiché. Veuillez confirmer ces modifications.
Une fois le déploiement terminé, le terminal affichera l’URL de base de vos APIs, vous permettant de les tester.

Tests
Avec notre application maintenant déployée, il est temps de tester.
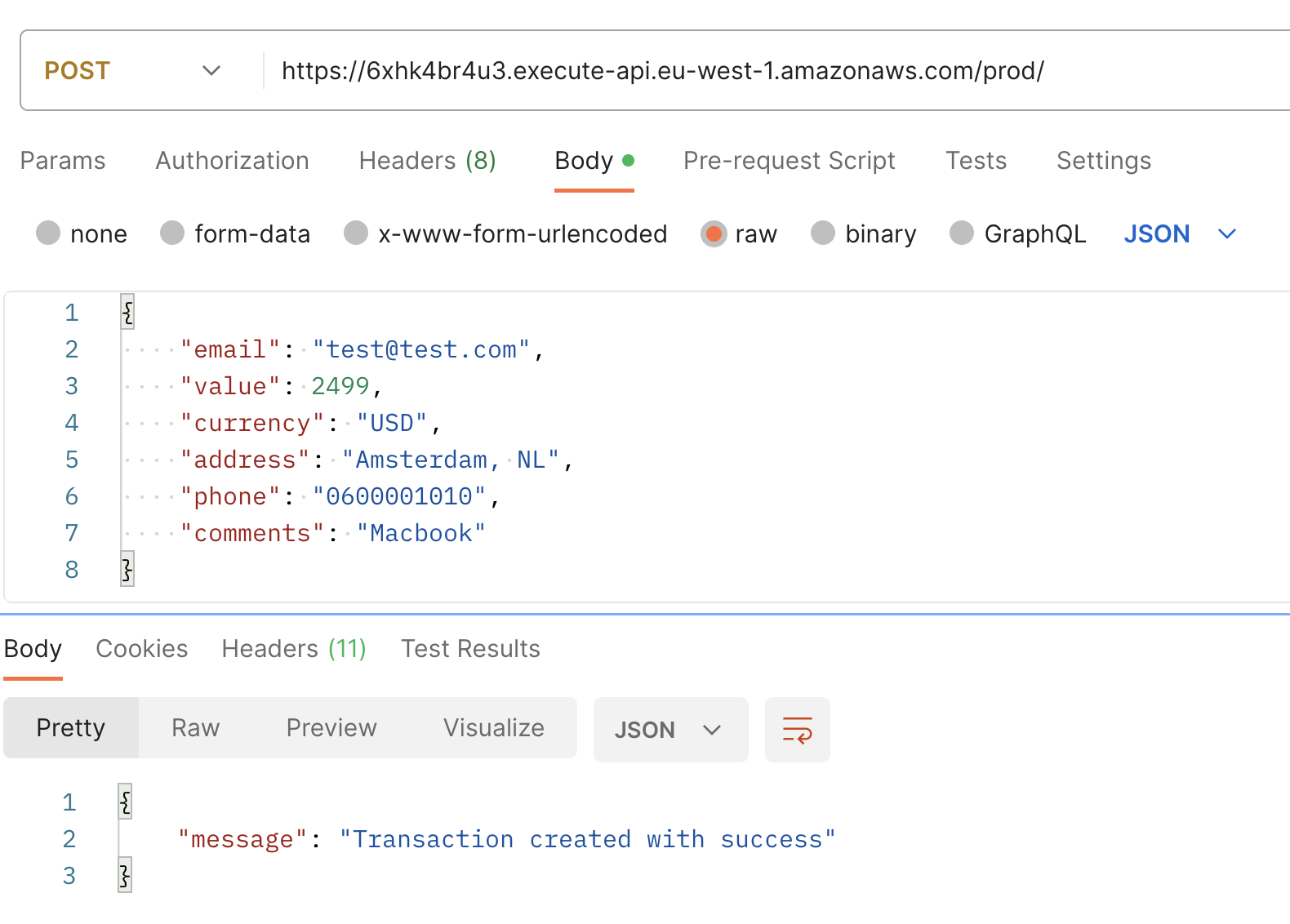
Utilisez l’URL de base affichée dans votre console pour faire une requête POST, en utilisant la charge utile suivante. En réponse, vous devriez recevoir un message indiquant “Transaction created with success.”
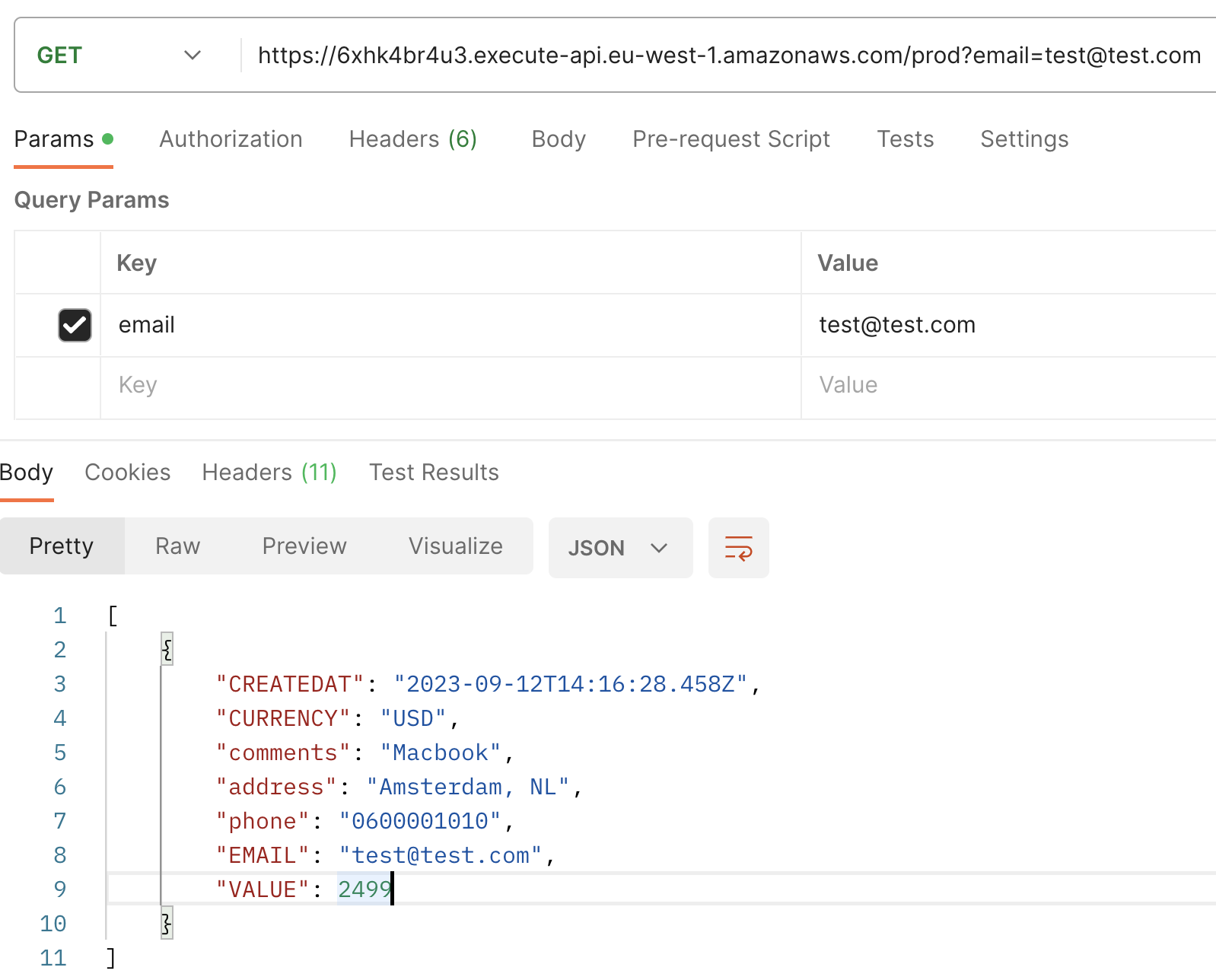
Ensuite, lorsque vous exécutez une requête GET avec email comme paramètre de requête, vous observerez la transaction récemment créée, maintenant incrémentée avec un champ supplémentaire : CREATEDAT.
Et nous avons enfin terminé. 🎉🎉🎉
Vous pouvez trouver le projet complet sur GitHub.
Questions ou suggestions, merci de laisser un commentaire, nous sommes tous ici pour apprendre ensemble. 🤠
Merci de votre lecture !


