
Oggi impareremo a conoscere l’AWS CDK, che è uno strumento molto utile per creare la tua infrastruttura nel cloud AWS.
Con CDK, puoi creare rapidamente infrastrutture tramite codice e utilizzando linguaggi che usiamo già nella nostra vita quotidiana, come TypeScript, Python, Java. Quindi, per ridurre la complessità della gestione della tua infrastruttura e fare tutto in modo automatizzato, CDK potrebbe essere l’opzione ideale per te.
IaC
Prima di parlare di CDK è importante capire cosa sia l’infrastruttura come codice
L’infrastruttura come codice (IaC) è un modo di creare e gestire risorse infrastrutturali usando il codice invece di configurare tutto tramite una pagina web o comandi in un terminale.
Diciamo che hai bisogno di creare un server web nel cloud. Invece di andare alla console di AWS e cliccare su una serie di pulsanti per creare manualmente il tuo server, puoi scrivere codice che dettaglia tutte le configurazioni del server, come il tipo di istanza, la dimensione del disco, quanta memoria avrà questo server e le impostazioni di rete.
Puoi poi eseguire questo codice per creare e configurare automaticamente il server su AWS. Questo è utile perché puoi ripetere il processo tutte le volte che vuoi, senza preoccuparti di dimenticare una configurazione importante, e puoi anche gestire queste risorse come se fossero codice, salvandole nel tuo repository git, avendo tutta la cronologia delle modifiche e, ovviamente, facendo code reviews nel tuo codice dell’infrastruttura.
L’infrastruttura come codice può sembrare complicata, ma non lo è. Al giorno d’oggi, nessuno configura applicazioni manualmente, i rischi di farlo in vere applicazioni sono troppo alti. Ecco perché gli strumenti per l’infrastruttura come codice (come CDK) sono così importanti. E tra l’altro, molto più divertente che cliccare sui pulsanti, no?!
CDK & Cloud Formation
Ci sono diversi strumenti di infrastruttura come codice sul mercato. Qui, più nel contesto di AWS, parliamo di CDK e CloudFormation. Entrambi sono strumenti che aiutano gli sviluppatori a costruire e gestire risorse infrastrutturali nel cloud. Il CDK è stato creato sopra l’add-on di CloudFormation e spiegherò il perché.
CloudFormation è più vecchio e utilizza file JSON o YAML per descrivere l’infrastruttura che si desidera costruire. È necessario sapere come scrivere questi file nella sintassi corretta e a volte può essere un po’ disordinato e i file possono diventare abbastanza grandi. Con CloudFormation, descrivi esattamente come sarà la tua infrastruttura.
AWS CDK è un po’ diverso poiché ti permette di utilizzare linguaggi di programmazione come TypeScript, Python, Java per descrivere la tua infrastruttura. Puoi creare infrastrutture complesse e sofisticate usando classi e oggetti, il che rende il codice dell’infrastruttura più familiare per gli sviluppatori.
Inoltre, con CDK, puoi riutilizzare e condividere codice per risparmiare tempo. È possibile creare componenti e condividerli nella tua azienda, creando librerie, ad esempio, che abbiano configurazioni standard che possono essere utilizzate da diversi team nella tua azienda. E naturalmente ci sono componenti open source realizzati dalla community.
E perché ho detto che CDK è un add-on di CloudFormation? Perché quando compiliamo questo codice CDK, ciò che verrà generato è un file CloudFormation, che verrà utilizzato per creare la nostra infrastruttura.
Quindi, CDK è sempre la scelta migliore? NO! Una cosa che devi sempre tenere a mente è che il CDK è una soluzione opinata. Cosa intendo con questo? CDK è uno strumento costruito sopra CloudFormation, e per questo ci sono diversi comportamenti predefiniti in questo strumento, che generalmente rendono il codice CDK più piccolo rispetto a CloudFormation, e questo non significa che questi comportamenti non cambino con nuove versioni. CloudFormation può essere molto verbose e un po’ più complicato da usare, ma d’altra parte, con CloudFormation descrivi esattamente come dovrebbe essere la tua infrastruttura.
Quindi, tenendo ciò a mente, può darsi che per alcune aree più sensibili della tua infrastruttura, CDK non sia la scelta migliore. OK? Spero che la differenza sia chiara.
Applicazione
Prima di entrare nel codice, è necessario avere installato il CDK CLI. Lascio il link nella descrizione, dove puoi seguire passo dopo passo.
Diamo un’occhiata rapida all’implementazione dell’applicazione e poi iniziamo a costruire l’infrastruttura insieme.
La nostra applicazione è semplice e ha due endpoint:
- Un endpoint di tipo POST per registrare transazioni.
- Dove passiamo un payload con email, valore, valuta, ecc.
- Un endpoint GET per elencare tutte le transazioni effettuate nel giorno
- dove avremo i dati che abbiamo registrato, più la data in cui è stata effettuata la transazione e un ID
I due endpoint saranno eseguiti tramite lambdas insieme ad API Gateway e i dati salvati in un database DynamoDB.
Il link al codice su Github è anche nella descrizione.
Non entrerò nei dettagli sull’implementazione dell’applicazione, perché non è il focus di questo video. Sono solo 2 lambdas, una che salva i dati nel nostro database DynamoDB e l’altra che li recupera. Se vuoi sapere di più su Lambdas e DynamoDB, lascia un commento e farò altri video a riguardo.
E inoltre iscriviti al canale e lascia un like per aiutare il canale a crescere e per permettermi di fare più video.
Progetto e dipendenze
Se guardiamo nella documentazione, vedremo che è possibile creare un progetto usando il comando cdk init. Questo progetto è stato creato utilizzando questo comando e ho aggiunto alcune altre dipendenze:
@aws-cdk/aws-lambda-nodejs
@types/aws-lambda
aws-sdk
- @aws-cdk/aws-lambda-nodejs e @types/aws-lambda
- per configurare facilmente le nostre lambda con NodeJS
- aws-sdk
- per utilizzare DynamoDB
#!/usr/bin/env node
import 'source-map-support/register';
import * as cdk from 'aws-cdk-lib';
import { InitWithCDKTypescriptStack } from '../lib/init-with-cdk-typescript-stack';
const app = new cdk.App();
new InitWithCDKTypescriptStack(app, 'InitWithCdkTypescriptStack');
Stacks
Il punto di ingresso per un codice CDK per iniziare a costruire la nostra infrastruttura è la cartella bin.
All’interno di quella cartella, avremo un file che verrà creato insieme al progetto, ed è questo file che inizierà ad assemblare la nostra infrastruttura.
Possiamo vedere che la prima riga è la creazione di una nuova applicazione CDK e poi creiamo un nuovo stack e gli diamo un id.
In CDK, uno “stack” è fondamentalmente una raccolta di componenti che si possono creare. È un insieme di componenti che si possono impilare e disporre in modo che abbia senso per voi. Ovviamente, si può avere un solo stack, oppure se ne possono avere diversi e organizzarli come si preferisce.
Per esempio, diciamo che si vuole costruire un’applicazione web su AWS. Si può creare un singolo stack che conterrà la propria istanza EC2 per ospitare l’applicazione, le impostazioni di sicurezza, un bucket S3 per memorizzare i file e così via.
Oppure un altro esempio potrebbe essere la divisione per stack che contengono servizi che ospitano dati e altri che non lo fanno. Quindi, s3 e DynamoDB su uno stack, lambdas e API Gateway su un altro.
Per creare uno stack, abbiamo bisogno di una classe che estenda cdk.stack e all’interno di quella classe possiamo iniziare a elencare i componenti che apparterranno a quello stack.
È bene menzionare che gli stack e i componenti che andremo a creare si trovano nella cartella lib. La cartella bin è utilizzata solo per indicare al CDK dove inizia la dichiarazione dell’infrastruttura.
DynamoDB Stack
Per prima cosa creiamo il nostro database DynamoDB. All’interno di un nuovo file, creiamo una classe TransactionsTable e estendiamola da Table.
import { AttributeType, Table } from "aws-cdk-lib/aws-dynamodb";
import { Construct } from "constructs";
export class TransactionsTable extends Table {
constructor(scope: Construct) {
super(scope, 'TRANSACTIONS_TABLE', {
partitionKey: { name: 'EMAIL', type: AttributeType.STRING },
sortKey: { name: 'CREATEDAT', type: AttributeType.STRING },
});
}
}
La classe ha un costruttore che riceve un parametro chiamato scope, di tipo Construct. Questo parametro rappresenta l’ambito in cui la tabella viene creata. Nel nostro caso, questo ambito sarà il nostro stack principale, InitWithCDKTypescriptStack.
All’interno del costruttore della classe Table, dobbiamo inserire alcune informazioni importanti. Prima di tutto, diamo alla tabella un nome, che è 'TRANSACTIONS_TABLE'.
Un consiglio rapido su questo: quando chiamiamo il database nel nostro codice e vogliamo utilizzare la tabella che stiamo creando, non è possibile chiamare la tabella utilizzando solo questo nome. I nomi delle risorse in AWS devono essere unici, quindi la tabella verrà creata con il nome che abbiamo dato e AWS aggiungerà qualche identificatore per renderlo unico. Per poter usare questa tabella, nel codice dell’applicazione possiamo vedere che otteniamo il vero nome della tabella tramite una variabile d’ambiente. Poi basta usare questa variabile come TableName.
Ritornando al codice dell’infrastruttura, successivamente specifichiamo il partitionKey e il sortKey per la tabella. Il partitionKey può essere usato per identificare univocamente ogni elemento nella tabella. Questo non è il nostro caso, dato che la nostra chiave di partizione è il campo 'EMAIL' e, ovviamente, possiamo avere più di una transazione con la stessa email.
Stiamo usando il campo 'CREATEDAT' come chiave di ordinamento. Il sortKey è sempre la data e l’ora in cui questa transazione è stata creata e lo useremo nella nostra API GET per filtrare le transazioni solo a quelle effettuate oggi.
Il trucco qui è che la combinazione di queste due chiavi è ciò che rende realmente unica questa transazione. Questa combinazione è chiamata Composite Key.
Lambdas
Passiamo ora al nostro codice lambdas. Adesso creiamo i nostri 2 lambdas. Iniziamo con il nostro lambda POST. Anche in questo caso creeremo una classe e questa volta la estenderemo da NodeJSFunction.
import { NodejsFunction } from "aws-cdk-lib/aws-lambda-nodejs";
import { Construct } from "constructs";
import { Runtime } from "aws-cdk-lib/aws-lambda";
import { Table } from "aws-cdk-lib/aws-dynamodb";
interface PostNewTransactionLambdaParams {
transactionsTable: Table
}
export class PostNewTransactionLambda extends NodejsFunction {
constructor(scope: Construct, params: PostNewTransactionLambdaParams) {
super(scope, 'NewTransactionLambda', {
runtime: Runtime.NODEJS_18_X,
memorySize: 256,
bundling: {
minify: true,
sourceMap: true,
},
entry: "application/src/lambda/newTransactionLambda.ts",
handler: "handler",
environment: {
TRANSACTIONS_TABLE: params.transactionsTable.tableName
}
});
params.transactionsTable.grantReadWriteData(this);
}
}
Nel costruttore, riceveremo nuovamente il scope e un nuovo parametro, params, che è di tipo PostNewTransactionLambdaParams. Definiamo questa interfaccia sopra e usiamo questo params per ricevere un riferimento alla tabella che abbiamo creato, che useremo subito sotto.
Ora alcune impostazioni per la nostra lambda:
- Versione di NodeJS: in questo caso, useremo l’ultima LTS, che è la 18.
- Quantità di memoria che questa lambda alloccherà: 256 MB.
- Impostazioni di bundling per comprimere il nostro codice e rimuovere dal pacchetto finale ciò che non è necessario.
- Ora, indichiamo quale lambda appartiene a questa configurazione. Quindi, passiamo il percorso del file lì e, in
handler, il nome della funzione di input in quel file, che, nel nostro caso, si chiama anchehandler. - Ricordi che ho detto che, per accedere al database, dobbiamo ottenere il nome della tabella tramite una variabile di ambiente? Per questo, dobbiamo definire quali variabili di ambiente avrà questa lambda. Quindi creiamo la nostra variabile di ambiente per il nome della tabella e usiamo il riferimento che abbiamo alla nostra tabella per ottenere il nome effettivo di quella tabella in AWS.
- Successivamente, utilizzeremo anche questo riferimento alla tabella per concedere permessi di scrittura e lettura alla nostra lambda.
E la nostra configurazione è pronta. Ora la nostra lambda GET è esattamente la stessa, cambieremo solo il percorso della lambda e l’interfaccia dei parametri. Anche in un progetto reale, potresti creare una classe base che abbia tutte queste impostazioni predefinite per tutte le tue lambdas.
import { Table } from "aws-cdk-lib/aws-dynamodb";
import { Runtime } from "aws-cdk-lib/aws-lambda";
import { NodejsFunction } from "aws-cdk-lib/aws-lambda-nodejs";
import { Construct } from "constructs";
interface TodayTransactionsLambdaParams {
transactionsTable: Table
}
export class GetTodayTransactionsLambda extends NodejsFunction {
constructor(scope: Construct, params: TodayTransactionsLambdaParams) {
super(scope, 'TodayTransactionsLambda', {
runtime: Runtime.NODEJS_18_X,
memorySize: 256,
bundling: {
minify: true,
sourceMap: true,
},
entry: "application/src/lambda/todayTransactionsLambda.ts",
handler: "handler",
environment: {
TRANSACTIONS_TABLE: params.transactionsTable.tableName
}
});
params.transactionsTable.grantReadData(this);
}
}
API Gateway
Procediamo con la creazione del nostro componente finale, l’API Gateway.
Invece di estendere una classe con un componente specifico, come abbiamo fatto con la tabella e le funzioni lambda, useremo un componente più generico qui, noto come Construct. È cruciale notare che tutti gli altri componenti che abbiamo utilizzato sono essenzialmente anche essi Constructs, dietro le quinte.
import { NodejsFunction } from "aws-cdk-lib/aws-lambda-nodejs";
import * as apiGateway from "aws-cdk-lib/aws-apigateway";
import { Construct } from "constructs";
interface TransactionsGatewayParams {
postNewTransactionsLambda: NodejsFunction,
getTodayTransactionsLambda: NodejsFunction,
}
export class TransactionsGateway extends Construct {
constructor(scope: Construct, params: TransactionsGatewayParams) {
super(scope, 'TransactionsGateway');
const api = new apiGateway.RestApi(this, "TransactionsApi", {
restApiName: "New Transactions API",
description: "Backend Horizon - New Transactions API",
});
api.root.addMethod("POST", new apiGateway.LambdaIntegration(params.postNewTransactionsLambda, {
requestTemplates: { "application/json": '{ "statusCode": "200" }' },
}));
api.root.addMethod("GET", new apiGateway.LambdaIntegration(params.getTodayTransactionsLambda, {
requestTemplates: { "application/json": '{ "statusCode": "200" }' },
}));
}
}
Definiremo un costruttore che prenderà i parametri scope e params, i quali conterranno riferimenti alle nostre due funzioni lambda.
Il prossimo passo consiste nella creazione di una nuova Rest API. Questa API appena creata sarà configurata con diversi parametri:
- Passeremo la nostra classe
TransactionsGatewaycome primo parametro. - Successivamente, assegneremo un ID a questa API, che chiameremo
TransactionsApi. - Inoltre, imposteremo un nome e una descrizione per questa API.
Il passo successivo consiste nel collegare le nostre lambda a questa Rest API. Aggiungeremo un metodo POST alla radice della nostra API. L’integrazione tra la nostra funzione lambda postNewTransactionsLambda e questa API verrà effettuata tramite una LambdaIntegration. Inoltre, specificheremo il formato della risposta che questa API restituirà. Tra le varie opzioni disponibili nella documentazione, sceglieremo di utilizzare il modello application/json, insieme al codice di stato (statusCode), che è una pratica comune.
Successivamente, ripeteremo questo processo per la funzione lambda getTodayTransactionsLambda, ma questa volta, configurandola come metodo GET.
Main Stack
Ora che tutti i nostri componenti sono stati creati, è il momento di connetterli. Sarà piuttosto semplice.
import * as cdk from 'aws-cdk-lib';
import { Construct } from 'constructs';
import { TransactionsTable } from './dynamodb/transactions-table';
import { TransactionsGateway } from './gateway/transactions-gateway';
import { GetTodayTransactionsLambda } from './lambdas/get-today-transactions-lambda';
import { PostNewTransactionLambda } from './lambdas/post-new-transaction-lambda';
export class InitWithCDKTypescriptStack extends cdk.Stack {
constructor(scope: Construct, id: string, props?: cdk.StackProps) {
super(scope, id, props);
const transactionsTable = new TransactionsTable(this);
const postNewTransactionsLambda = new PostNewTransactionLambda(this, { transactionsTable });
const getTodayTransactionsLambda = new GetTodayTransactionsLambda(this, { transactionsTable });
new TransactionsGateway(this, { postNewTransactionsLambda: postNewTransactionsLambda, getTodayTransactionsLambda });
}
}
Innanzitutto, prendiamo il componente TransactionsTable, che abbiamo sviluppato in precedenza. Quando creiamo questo componente, passeremo il nostro Stack come argomento per il parametro scope.
Successivamente, istanzieremo e integreremo i nostri due lambdas. Entrambi richiederanno lo Stack e il nuovo transactionsTable come parametri.
Il nostro ultimo passo in questa fase consiste nel configurare il nostro Gateway. Qui, forniremo lo stack attuale e i lambdas che abbiamo configurato in precedenza come argomenti.
Con questo, la costruzione principale del nostro Stack si conclude. Il passo successivo è il deployment di questo stack e dell’applicazione su AWS.
Deploy
Prima di distribuire la nostra applicazione, dobbiamo avviare il processo di “bootstrapping”. Questo è un passaggio preliminare da eseguire una sola volta.
- Inizia eseguendo il comando
npm run cdk bootstrap. - Al termine con successo, procedi con il deployment usando
npm run cdk deploy. Verrà visualizzata una panoramica delle modifiche in attesa. Si prega di confermare queste modifiche.
Una volta conclusa la distribuzione, il terminale mostrerà l’URL base per le tue API, permettendoti di testarle.

Testing
Con la nostra applicazione ora distribuita, è il momento di testare.
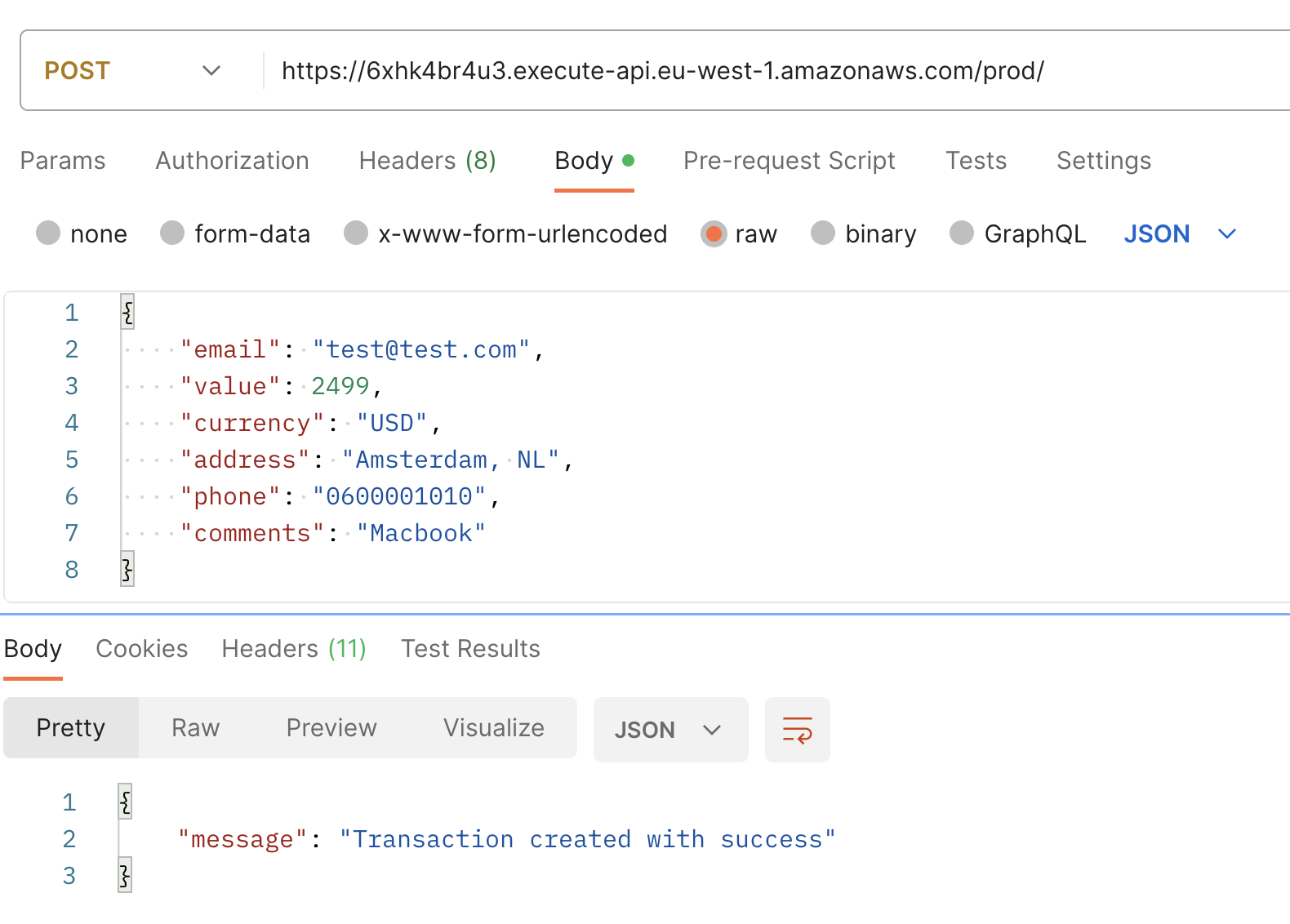
Utilizza l’URL di base visualizzato nella tua console per effettuare una POST request, usando il seguente payload di esempio. In risposta, dovresti ricevere un messaggio che dice “Transaction created with success.”
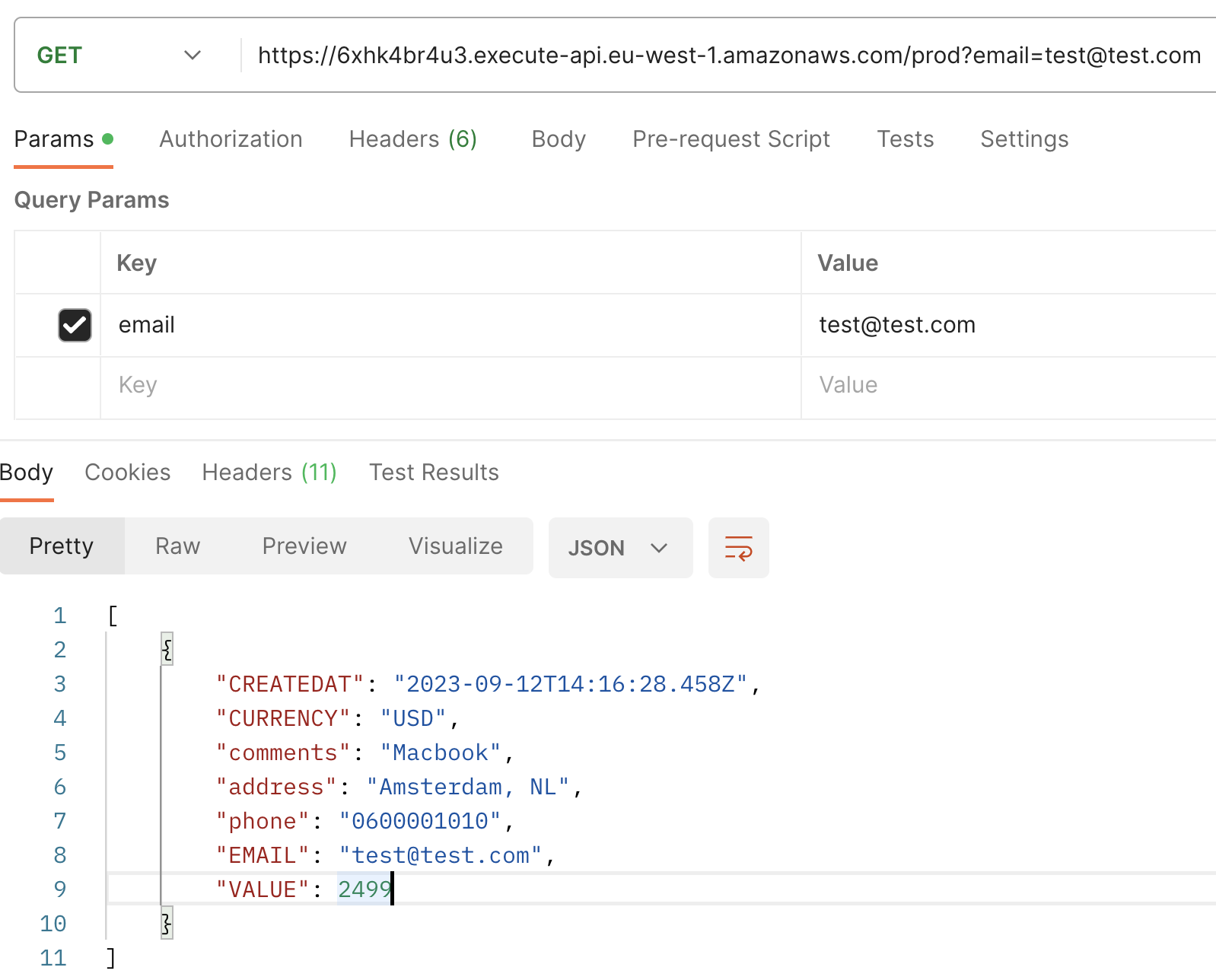
Successivamente, quando esegui una GET request con l’email come parametro di query, osserverai la transazione recentemente creata, ora incrementata con un campo aggiuntivo: CREATEDAT.
E finalmente abbiamo finito. 🎉🎉🎉
Puoi trovare il progetto completo su GitHub.
Domande o suggerimenti, lascia un commento, siamo tutti qui per imparare insieme. 🤠
Grazie per aver letto!


