
Hoje vamos aprender sobre o AWS CDK, que é uma ferramenta super útil para você criar sua infraestrutura na nuvem da AWS.
Com o CDK, você pode criar rapidamente infraestrutura via código e usando linguagens que já usamos em nosso dia a dia, como TypeScript, Python, Java. Então, para reduzir a complexidade de gerenciar sua infraestrutura e tudo de uma forma automatizada, o CDK pode ser a opção ideal para você.
IaC
Antes de falarmos sobre CDK, é importante entender o que é infraestrutura como código.
Infrastructure as code (IaC) é uma maneira de criar e gerenciar recursos de infraestrutura usando código em vez de configurar tudo através de uma página web ou por comandos em um terminal.
Vamos dizer que você precisa criar um servidor web na nuvem. Em vez de ir ao console da AWS e clicar em vários botões para criar seu servidor manualmente, você pode escrever um código que detalhe todas as configurações do servidor, como o tipo de instância, tamanho do disco, quanta memória este servidor terá e configurações de rede.
Você pode então executar esse código para criar e configurar automaticamente o servidor na AWS. Isso é útil porque você pode repetir o processo quantas vezes quiser, sem se preocupar em esquecer uma configuração importante, e também pode gerenciar esses recursos como se fossem código, salvar em seu repositório git, ter todo o histórico de alterações e, claro, fazer revisões de código em seu código de infraestrutura.
Infrastructure by code pode parecer complicado, mas não é. Hoje em dia, ninguém configura aplicações manualmente, os riscos de fazer isso em aplicações reais são muito altos. É por isso que ferramentas de infraestrutura como código (como CDK) são tão importantes. E, a propósito, muito mais divertido do que clicar em botões, certo?!
CDK & Cloud Formation
Existem várias ferramentas de infraestrutura como código no mercado. Aqui, mais no contexto da AWS, vamos falar sobre CDK e CloudFormation. Ambos são ferramentas que ajudam os desenvolvedores a construir e gerenciar recursos de infraestrutura na nuvem. O CDK foi feito em cima do complemento CloudFormation, e vou explicar o porquê.
CloudFormation é mais antigo e usa arquivos JSON ou YAML para descrever a infraestrutura que você deseja construir. Você precisa saber como escrever esses arquivos na sintaxe correta e, às vezes, pode ser um pouco confuso e os arquivos podem ficar bastante grandes. Com CloudFormation, você descreve precisamente como sua infraestrutura será.
AWS CDK é um pouco diferente, pois permite que você use linguagens de programação como TypeScript, Python, Java para descrever sua infraestrutura. Você pode criar infraestruturas complexas e sofisticadas usando classes e objetos, o que torna o código de infraestrutura mais familiar para os desenvolvedores.
Além disso, com CDK, você pode reutilizar e compartilhar código para economizar tempo. É possível criar componentes e compartilhá-los em sua empresa, criando bibliotecas, por exemplo, que possuem configurações padrão que podem ser usadas por várias equipes em sua empresa. E, claro, há componentes de código aberto feitos pela comunidade.
E por que eu disse que o CDK é um complemento do CloudFormation? Porque quando compilamos este código CDK, o que será gerado é um arquivo CloudFormation, que será usado para criar nossa infraestrutura.
Então o CDK é a melhor opção sempre? NÃO! Uma coisa que você sempre precisa ter em mente é que o CDK é uma solução opinativa. O que eu quero dizer com isso? O CDK é uma ferramenta construída sobre o CloudFormation, e por causa disso, há vários comportamentos padrão nesta ferramenta, o que geralmente torna o código CDK menor em comparação com o CloudFormation, e isso não significa que esses comportamentos não mudem com novas versões. CloudFormation pode ser muito verboso e um pouco mais difícil de trabalhar, mas, por outro lado, com CloudFormation você descreve precisamente como sua infraestrutura deve ser.
Então, com isso em mente, pode ser que para algumas áreas mais sensíveis de sua infraestrutura, o CDK não seja a melhor opção. OK? Espero que a diferença esteja clara.
Application
Antes de entrarmos no código, você precisa ter o CDK CLI instalado. Vou deixar o link na descrição, onde você pode seguir o passo a passo.
Vamos dar uma olhada rápida na implementação da aplicação e então começaremos a construir a infraestrutura juntos.
Nossa aplicação é simples e possui dois endpoints:
- Um endpoint do tipo POST para registrar transações.
- Onde passamos um payload com email, valor, moeda, etc.
- Um endpoint GET para listar todas as transações realizadas no dia
- onde teremos os dados que registramos, além da data em que a transação foi efetuada e um ID
Os dois endpoints serão executados via lambdas juntamente com API Gateway e os dados salvos em um banco de dados DynamoDB.
O link para o código no Github também está na descrição.
Eu não vou entrar em detalhes sobre a implementação da aplicação, porque não é o foco deste vídeo. São apenas 2 lambdas, uma salvando dados no nosso banco de dados DynamoDB e a outra buscando-os. Se você quiser saber mais sobre Lambdas e DynamoDB, deixe um comentário e farei outros vídeos sobre isso.
E também assine o canal e deixe um like para ajudar o canal a crescer e eu poder fazer mais vídeos.
@aws-cdk/aws-lambda-nodejs
@types/aws-lambda
aws-sdk
Projeto e dependências
Se olharmos na documentação, veremos que é possível criar um projeto usando o comando cdk init. Este projeto foi criado usando este comando e eu adicionei algumas outras dependências:
- @aws-cdk/aws-lambda-nodejs e @types/aws-lambda
- para configurar facilmente nossas lambdas com NodeJS
- aws-sdk
- para usarmos o DynamoDB
Stacks
O ponto de entrada para um código CDK começar a construir nossa infraestrutura é a pasta bin.
Dentro dessa pasta, teremos um arquivo que será criado junto com o projeto, e é esse arquivo que começará a montar nossa infraestrutura.
#!/usr/bin/env node
import 'source-map-support/register';
import * as cdk from 'aws-cdk-lib';
import { InitWithCDKTypescriptStack } from '../lib/init-with-cdk-typescript-stack';
const app = new cdk.App();
new InitWithCDKTypescriptStack(app, 'InitWithCdkTypescriptStack');
Podemos ver que a primeira linha é a criação de um novo aplicativo CDK e depois criamos uma nova pilha e damos a ela um id.
No CDK, uma “pilha” é basicamente uma coleção de componentes que você pode criar. É um conjunto de componentes que você pode empilhar e organizar de uma maneira que faça sentido para você. Claro, você pode ter apenas uma pilha, ou pode ter várias e organizá-las da maneira que preferir.
Por exemplo, digamos que você queira construir um aplicativo web na AWS. Você pode criar uma única pilha que terá sua instância EC2 para hospedar o aplicativo, configurações de segurança, um bucket S3 para armazenar arquivos e assim por diante.
Ou outro exemplo seria dividir por pilhas que contêm serviços que hospedam dados e outros que não. Então, s3 e DynamoDB em uma pilha, lambdas e API Gateway em outra.
Para criar uma pilha, precisamos de uma classe que estenda cdk.stack e dentro dessa classe podemos começar a listar os componentes que pertencerão a essa pilha.
É bom mencionar que as pilhas e os componentes que vamos criar estão na pasta lib. A pasta bin é usada apenas para sinalizar ao CDK onde começa a declaração da infraestrutura.
DynamoDB Stack
Primeiro, vamos criar nosso banco de dados DynamoDB. Dentro de um novo arquivo, vamos criar uma classe TransactionsTable e estendê-la de Table.
import { AttributeType, Table } from "aws-cdk-lib/aws-dynamodb";
import { Construct } from "constructs";
export class TransactionsTable extends Table {
constructor(scope: Construct) {
super(scope, 'TRANSACTIONS_TABLE', {
partitionKey: { name: 'EMAIL', type: AttributeType.STRING },
sortKey: { name: 'CREATEDAT', type: AttributeType.STRING },
});
}
}
A classe possui um construtor que recebe um parâmetro chamado scope, do tipo Construct. Este parâmetro representa o escopo no qual a tabela está sendo criada. No nosso caso, este escopo será nossa stack principal, InitWithCDKTypescriptStack.
Dentro do construtor da classe Table, precisamos inserir algumas informações importantes. Primeiro, damos um nome à tabela, que é 'TRANSACTIONS_TABLE'.
Dica rápida sobre isso: quando chamamos o banco de dados no nosso código e queremos usar a tabela que estamos criando, não é possível chamar a tabela usando apenas este nome. Nomes de recursos na AWS precisam ser únicos, então a tabela será criada com o nome que fornecemos e a AWS adicionará algum identificador para torná-lo único. Para poder usar essa tabela, no código da aplicação podemos ver que obtemos o nome real da tabela através de uma variável de ambiente. Então, apenas usamos essa variável como TableName.
Retornando ao código de infra, em seguida especificamos o partitionKey e o sortKey para a tabela. O partitionKey pode ser usado para identificar exclusivamente cada item na tabela. Este não é o nosso caso, pois nossa chave de partição é o campo 'EMAIL' e, claro, podemos ter mais de uma transação com o mesmo email.
Estamos usando o campo 'CREATEDAT' como a chave de ordenação. O sortKey é sempre a data e hora em que esta transação foi criada e vamos usá-lo em nossa API GET para filtrar as transações apenas para aquelas feitas hoje.
O truque aqui é que a combinação dessas duas chaves é o que realmente torna essa transação única. Essa combinação é chamada de Composite Key.
Lambdas
Passando para o nosso código de lambdas. Agora vamos criar nossas 2 lambdas. Vamos começar com a nossa lambda POST. Aqui novamente vamos criar uma classe e desta vez vamos estendê-la de NodeJSFunction.
import { NodejsFunction } from "aws-cdk-lib/aws-lambda-nodejs";
import { Construct } from "constructs";
import { Runtime } from "aws-cdk-lib/aws-lambda";
import { Table } from "aws-cdk-lib/aws-dynamodb";
interface PostNewTransactionLambdaParams {
transactionsTable: Table
}
export class PostNewTransactionLambda extends NodejsFunction {
constructor(scope: Construct, params: PostNewTransactionLambdaParams) {
super(scope, 'NewTransactionLambda', {
runtime: Runtime.NODEJS_18_X,
memorySize: 256,
bundling: {
minify: true,
sourceMap: true,
},
entry: "application/src/lambda/newTransactionLambda.ts",
handler: "handler",
environment: {
TRANSACTIONS_TABLE: params.transactionsTable.tableName
}
});
params.transactionsTable.grantReadWriteData(this);
}
}
No construtor, vamos novamente receber o scope e um novo parâmetro, params, que é do tipo PostNewTransactionLambdaParams. Vamos definir essa interface acima e usar esse params para receber uma referência à tabela que criamos, que usaremos logo abaixo.
Agora, algumas configurações para nossa lambda:
- Versão do NodeJS: neste caso, usaremos a mais recente LTS, que é a 18.
- Quantidade de memória que esta lambda irá alocar: 256 MB.
- Configurações de empacotamento para comprimir nosso código e tirar do pacote final o que não é necessário.
- Agora, vamos apontar qual lambda pertence a esta configuração. Então, passamos o caminho do arquivo e, no
handler, o nome da função de entrada nesse arquivo, que, no nosso caso, também se chamahandler. - Lembra que eu disse que, para acessar o banco de dados, precisamos obter o nome da tabela via uma variável de ambiente? Para isso, precisamos definir quais variáveis de ambiente essa lambda terá. Então, vamos criar nossa variável de ambiente com o nome da tabela e vamos usar a referência que temos para nossa tabela para obter o nome real dessa tabela na AWS.
- Em seguida, também vamos usar essa referência da tabela para dar permissões de escrita e leitura para nossa lambda.
E nossa configuração está pronta. Agora, nossa lambda de GET é exatamente a mesma, só vamos mudar o caminho da lambda e a interface dos parâmetros. Mesmo em um projeto real, você pode criar uma classe base que tenha todas essas configurações padrão para todas as suas lambdas.
import { Table } from "aws-cdk-lib/aws-dynamodb";
import { Runtime } from "aws-cdk-lib/aws-lambda";
import { NodejsFunction } from "aws-cdk-lib/aws-lambda-nodejs";
import { Construct } from "constructs";
interface TodayTransactionsLambdaParams {
transactionsTable: Table
}
export class GetTodayTransactionsLambda extends NodejsFunction {
constructor(scope: Construct, params: TodayTransactionsLambdaParams) {
super(scope, 'TodayTransactionsLambda', {
runtime: Runtime.NODEJS_18_X,
memorySize: 256,
bundling: {
minify: true,
sourceMap: true,
},
entry: "application/src/lambda/todayTransactionsLambda.ts",
handler: "handler",
environment: {
TRANSACTIONS_TABLE: params.transactionsTable.tableName
}
});
params.transactionsTable.grantReadData(this);
}
}
API Gateway
Vamos prosseguir com a criação do nosso componente final, o API Gateway.
Em vez de estender uma classe com um componente específico, como fizemos com a tabela e as funções lambda, usaremos um componente mais genérico aqui, conhecido como Construct. É crucial notar que todos os outros componentes que usamos também são essencialmente Constructs, nos bastidores.
import { NodejsFunction } from "aws-cdk-lib/aws-lambda-nodejs";
import * as apiGateway from "aws-cdk-lib/aws-apigateway";
import { Construct } from "constructs";
interface TransactionsGatewayParams {
postNewTransactionsLambda: NodejsFunction,
getTodayTransactionsLambda: NodejsFunction,
}
export class TransactionsGateway extends Construct {
constructor(scope: Construct, params: TransactionsGatewayParams) {
super(scope, 'TransactionsGateway');
const api = new apiGateway.RestApi(this, "TransactionsApi", {
restApiName: "New Transactions API",
description: "Backend Horizon - New Transactions API",
});
api.root.addMethod("POST", new apiGateway.LambdaIntegration(params.postNewTransactionsLambda, {
requestTemplates: { "application/json": '{ "statusCode": "200" }' },
}));
api.root.addMethod("GET", new apiGateway.LambdaIntegration(params.getTodayTransactionsLambda, {
requestTemplates: { "application/json": '{ "statusCode": "200" }' },
}));
}
}
Definiremos um construtor que receberá os parâmetros scope e params, que conterão referências para nossas duas funções lambda.
O próximo passo envolve criar uma nova API Rest. Esta API recém-criada será configurada com vários parâmetros:
- Passaremos nossa própria classe
TransactionsGatewaycomo o primeiro parâmetro. - Em seguida, atribuíremos um ID a esta API, que chamaremos de
TransactionsApi. - Além disso, definiremos um nome e uma descrição para esta API.
O próximo passo é conectar nossas lambdas a esta API Rest. Adicionaremos um método POST na raiz da nossa API. A integração entre nossa função lambda postNewTransactionsLambda e esta API será realizada através de uma LambdaIntegration. Além disso, especificaremos o formato de resposta que esta API retornará. Entre as várias opções disponíveis na documentação, escolheremos usar o modelo application/json, juntamente com o código de status (statusCode), o que é uma prática comum.
Depois disso, repetiremos esse processo para a função lambda getTodayTransactionsLambda, mas desta vez, configurando-a como um método GET.
Main Stack
Agora que todos os nossos componentes estão criados, é hora de conectá-los. Será bastante simples.
import * as cdk from 'aws-cdk-lib';
import { Construct } from 'constructs';
import { TransactionsTable } from './dynamodb/transactions-table';
import { TransactionsGateway } from './gateway/transactions-gateway';
import { GetTodayTransactionsLambda } from './lambdas/get-today-transactions-lambda';
import { PostNewTransactionLambda } from './lambdas/post-new-transaction-lambda';
export class InitWithCDKTypescriptStack extends cdk.Stack {
constructor(scope: Construct, id: string, props?: cdk.StackProps) {
super(scope, id, props);
const transactionsTable = new TransactionsTable(this);
const postNewTransactionsLambda = new PostNewTransactionLambda(this, { transactionsTable });
const getTodayTransactionsLambda = new GetTodayTransactionsLambda(this, { transactionsTable });
new TransactionsGateway(this, { postNewTransactionsLambda: postNewTransactionsLambda, getTodayTransactionsLambda });
}
}
Primeiramente, pegamos o componente TransactionsTable que desenvolvemos anteriormente. Ao criar este componente, passaremos nossa Stack como argumento para o parâmetro scope.
Em seguida, instanciamos e integramos nossas duas lambdas. Ambas precisarão da Stack e do recém-criado transactionsTable como parâmetros.
Nosso passo final nesta fase envolve configurar nosso Gateway. Aqui, forneceremos a stack atual e as lambdas que configuramos anteriormente como argumentos.
Com isso, a construção primária da nossa Stack está concluída. O próximo passo é implantar essa stack e a aplicação na AWS.
Deploy
Antes de implantar nossa aplicação, precisamos iniciar o processo de “bootstrapping”. Este é um passo pré-requisito único.
- Comece executando o comando
npm run cdk bootstrap. - Após a conclusão bem-sucedida, prossiga com a implantação usando
npm run cdk deploy. Uma visão geral das alterações pendentes será exibida. Por favor, confirme estas alterações.
Uma vez que a implantação conclua, o terminal exibirá a URL base para suas APIs, permitindo que você as teste.

Testing
Com nossa aplicação agora implantada, é hora de testar.
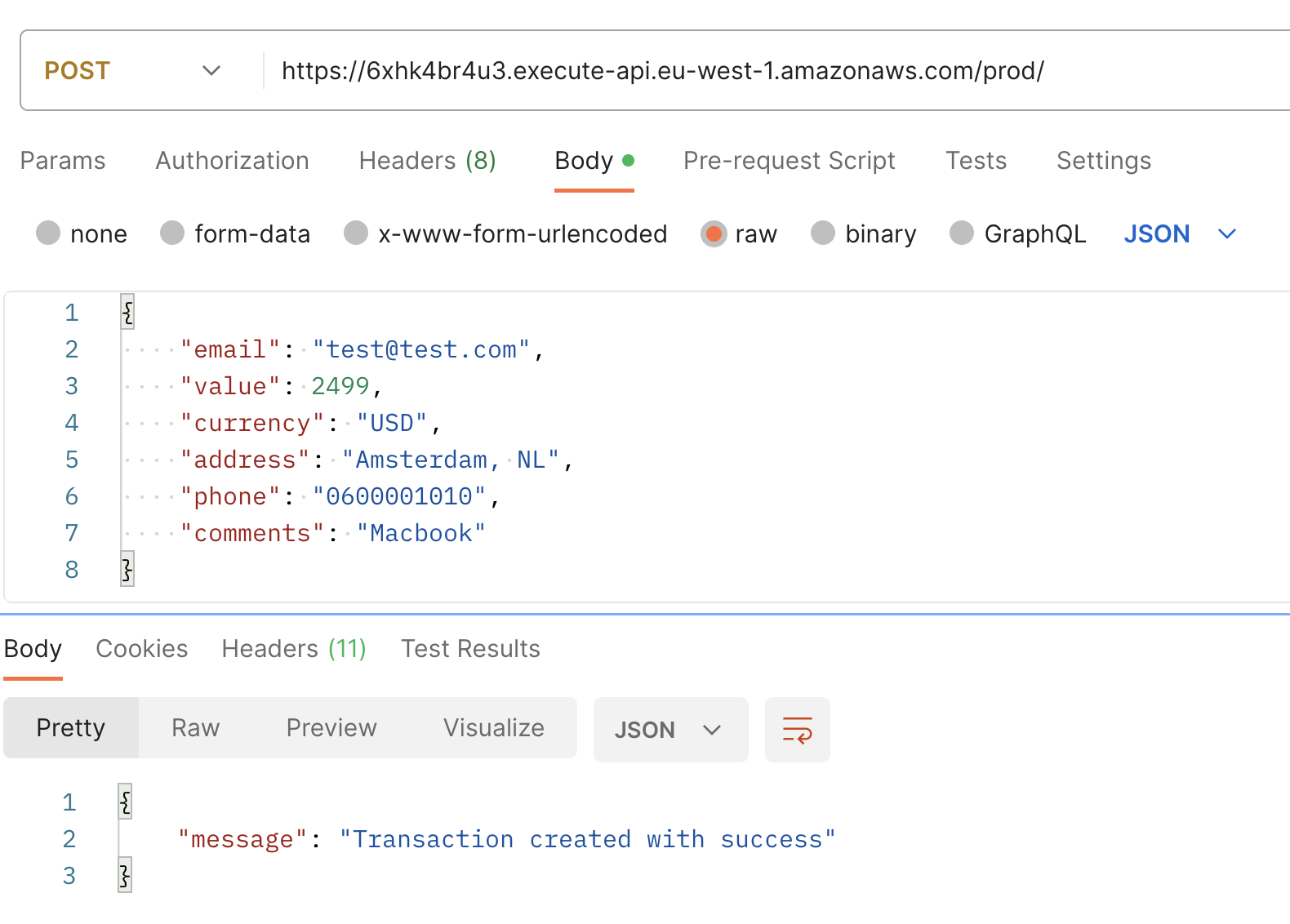
Utilize o URL base exibido no seu console para fazer uma POST request, usando o seguinte payload de exemplo. Em resposta, você deve receber uma mensagem afirmando “Transaction created with success.”
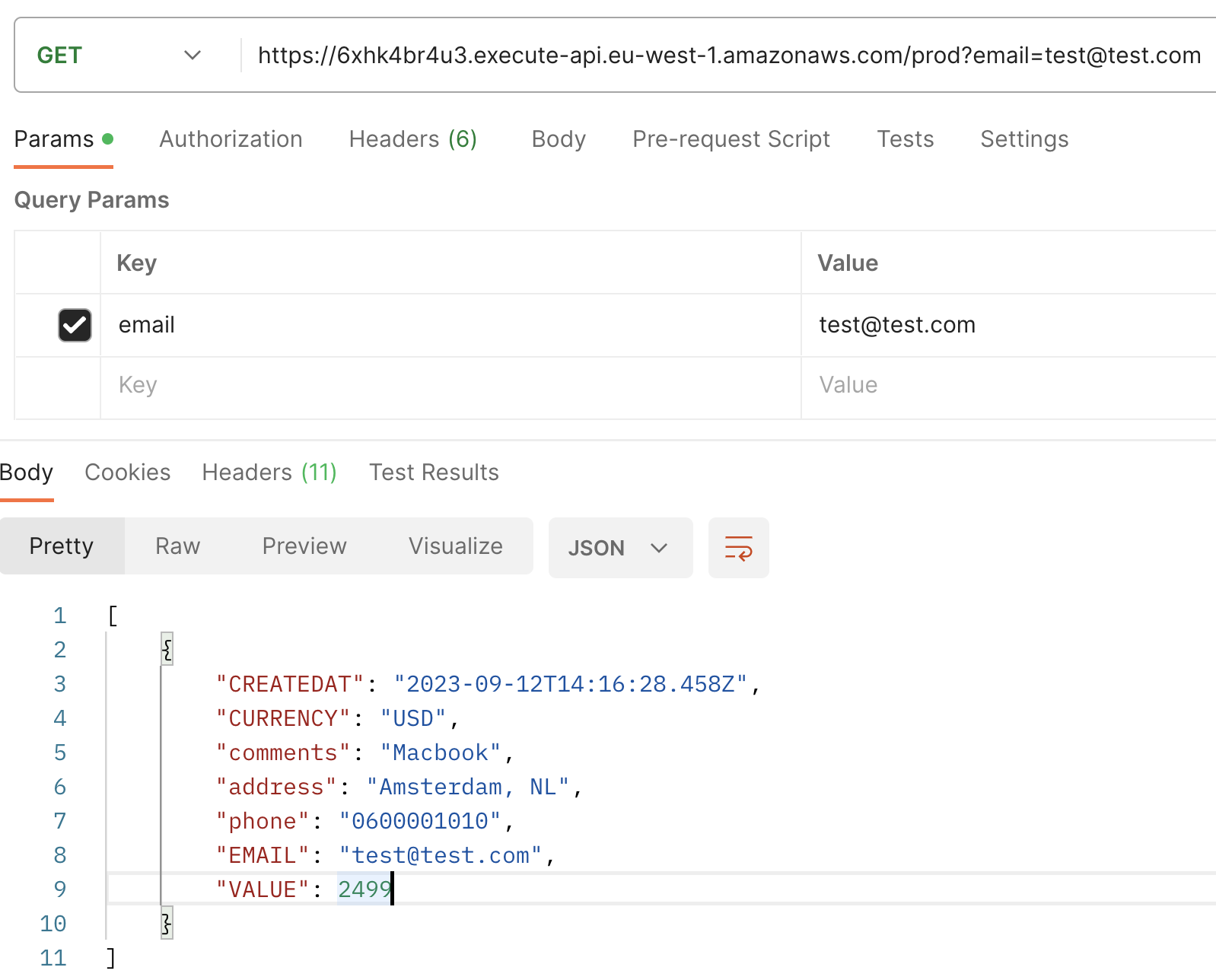
Em seguida, quando você executar uma GET request com email como parâmetro de consulta, você observará a transação recentemente criada, agora incrementada com um campo adicional: CREATEDAT.
E finalmente terminamos. 🎉🎉🎉
Você pode encontrar o projeto completo no GitHub.
Perguntas ou sugestões, por favor, deixe um comentário, estamos todos aqui para aprender juntos. 🤠
Obrigado por ler!


